A Manual Implementation of Quantization in PyTorch - Single Layer
Introduction
The packaging of extremely complex techniques inside convenient wrappers in PyTorch often makes quick implementations fairly easy, it also removes the need to understand the inner workings of the code. However, this obfuscates the theory of why such things work and why they are important to us. For instance, for neither love or money, could I figure out what a QuantStub and a DeQuant Stub really do and how to replicate that using pen and paper. In embedded systems one often has to code up certain things from scratch, as it were and sometimes PyTorch’s “convenience” can be a major impediment to understanding the underlying theory. In the code below, I will show you how to quantize a single layer of a neural network using PyTorch. And explain each step in excruciating detail. At the end of this article you will be able to implement quantization in PyTorch (or indeed any other library) but crucially, you will be able to do it without using any quantize layers, you can essentially use the usual “vanilla” layers. But before that we need to understand how or why quantization is important.
Quantization
The process of quantization is the process of reducing the number of bits that represent a number. This usually means we want to use an integer instead of a real number, that is, you want to go from using a floating point number to an integer. It is important to note that the reason for this is because of the way we multiply numbers in embedded systems. This has to do with both the physics and the chemistry of a half-adder and a full adder. It just takes longer to multiply two floats together than it does to multiply two integers together. For instance, multiplying
Outline
I start with the intuition behind Quantization using a helpful example. And then I outline a manual implementation of quantization in PyTorch. So what exactly does “manual” mean?
- I will take a given, assumed pre-trained, PyTorch model (1 Fully connected layer with no bias) that has been quantized using PyTorch’s quantization API.
- I will extract the weights of the layer and quantize them manually using the scale and zero point from the PyTorch quantization API.
- I will quantize the input to the layer manually, using the same scale and zero point as the PyTorch quantization API.
- I will construct a “vanilla” fully connected layer (as opposed to the quantized layer in step 1) and multiply the quantized weights and input to get the output.
- I will compare the output of the quantized layer from step 1 with the output of the “vanilla” layer from step 4.
This will inherently allow you to understand the following :
- How to quantize a layer in PyTorch and what quantizing in PyTorch really means.
- Some potentially confusing issues about what is being quantized, how and why.
- What does the QuantStub and DeQuantStub really do and how to replicate that using pen and paper.
At the end of this article you should be able to :
- Understand Quantization conceptually.
- Understand PyTorch’s quantization API.
- Implement quantization manually in PyTorch.
- Implement a Quantized Neural Network in PyTorch without using PyTorch’s quantization API.
Intuition behind Quantization
The best way to think about quantization is to think of it through an example. Let’s say you own a store, and you are printing labels for the prices of objects, but you want to economize on the number of labels you print. Assume here for simplicity that you can print a label that shows a price lower than the price of the product but not more. If you print tags for 0.20 cents, you get the following table, which shows a loss of 0.97 by printing 6 labels. This obviously didn’t save you much as you might as well have printed
| Price | Tags | Loss |
|---|---|---|
| 1.99 | 1.8 | -0.19 |
| 2.00 | 2 | 0.00 |
| 0.59 | 0.4 | -0.19 |
| 12.30 | 12 | -0.30 |
| 8.50 | 8.4 | -0.10 |
| 8.99 | 8.8 | -0.19 |
| 6 | -0.97 |
Maybe we can be more aggressive, by choosing tags rounded to the nearest dollar instead, we can obviously lose more money but we save on one whole tag!
| Price | Tags | Loss |
|---|---|---|
| 1.99 | 1 | -0.99 |
| 2.00 | 2 | 0.00 |
| 0.59 | 0 | -0.59 |
| 12.30 | 12 | -0.30 |
| 8.50 | 8 | -0.50 |
| 8.99 | 8 | -0.99 |
| 5 | -3.37 |
How about an even more aggressive one? We round to the nearest
| Price | Tags | Loss |
|---|---|---|
| 1.99 | 0 | -1.99 |
| 2.00 | 0 | -2.00 |
| 0.59 | 0 | -0.59 |
| 12.30 | 10 | -2.30 |
| 8.50 | 0 | -8.50 |
| 8.99 | 0 | -8.99 |
| 2 | -24.37 |
In this example, the price tags represent memory units and each price tag printed costs a certain amount of memory. Obviously, printing as many price tags as there are goods results in no loss of money but also the worst possible outcome as far as memory is concerned. Going the other way reducing the number of tags results in the largest loss in money.
Quantization as an (Unbounded) Optimization Problem
Clearly, this calls for an optimization problem, so we can set up the following one : let
Where
Issues with finding a solution
A popular assumption is to assume that the function is a rounding of a linear transformation. The constraint that minimizes
Quantization as Bounded Optimization Problem
In the previous section, our goal was to reduce the number of price tags we print, but it was not a bounded problem. In your average grocery story prices could run between
| Price | Label | Loss |
|---|---|---|
| 1.99 | 0 | -1.99 |
| 2 | 0 | -2 |
| 0.59 | -1 | -1.59 |
| 12.3 | 2 | -10.3 |
| 8.5 | 1 | -7.5 |
| 8.99 | 1 | -7.99 |
| 4 | -31.37 |
This gives the oft quoted quantization formula,
Implication of Quantization
We have shown that given some prices, we can quantize them to a smaller set of labels. Thus saving on the cost of labels. What if you remembered
| Price | Label | Loss | DeQuant | De-q loss |
|---|---|---|---|---|
| 1.99 | 0 | 1.99 | 3.90 | 1.91 |
| 2.00 | 0 | 2.00 | 3.90 | 1.90 |
| 0.59 | -1 | 1.59 | 0.00 | 0.59 |
| 12.30 | 2 | 10.3 | 11.71 | 0.59 |
| 8.50 | 1 | 7.50 | 7.80 | 0.69 |
| 8.99 | 1 | 7.99 | 7.80 | 1.18 |
| 4 | 31.37 | 6.87 |
Quantization of Matrix Multiplication
Using this we can create a recipe for quantization to help us in the case of neural networks. Recall that the basic unit of a neural network is the operation,
We can apply quantization to the weights and the input (
Our goal of trying to avoid the floating point multiplication between
Code
Consider the following original,
1 | class M(torch.nn.Module): |
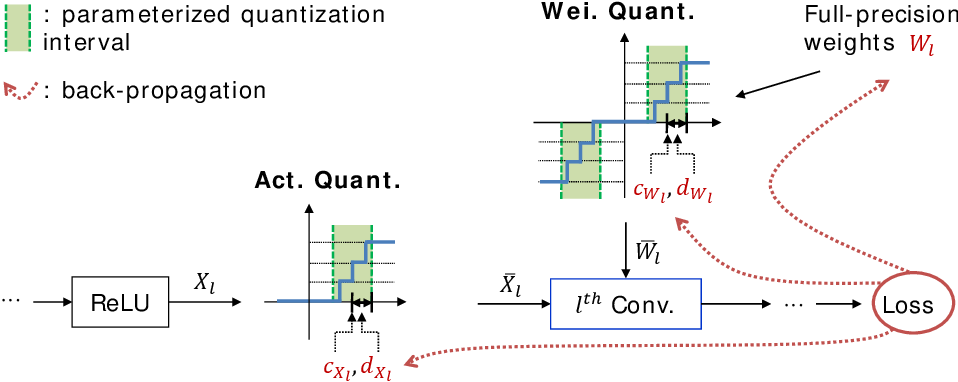
Now consider, the manual quantization of the weights and the input. model_int8 represents the quantized model. The QuantM2 class is the manual quantization of the model. The prepare_model function uses PyTorch convenience functions for quantization of the weights and the input i.e. get quantize_tensor_unsigned function is the manual quantization of the input tensor. The pytorch_result function is that computes the output of the fully connected layer of the PyTorch quantized model. The forward function is the manual quantization of the forward pass of the model.
1 |
|
Sample run code of the above code is as follows,
1 | cal_dat = torch.randn(1, 2) |
Let us start by analyzing the output of a quant layer of our simple model. The output of the int_models quantized layer is (somewhat counter-intuitively) always a float, this does not mean it is not quantized, it simply means you are shown the non-quantized value. If you look at the output, you will notice, it has dtype, quantization_scheme, scale and zero_point. You can view the value that will actually be used when it is called within the context of a quant layer by calling its int representation.
1 | #recreate quant layer |
Our manual quantization layer is a bit different, it outputs a QTensor object, which contains the tensor, the scale and the zero point. We get the scale and the zero point from the PyTorch quantized model’s quant layer (again, we could easily have done this by ourselves using the sample data).
1 | manual_quant_layer_output = quantize_tensor_unsigned(sample_data, int_model.quant(sample_data).q_scale(), int_model.quant(sample_data).q_zero_point()) |
Now let us look at the output of the quant layer AND the fully connected layer.
1 | #recreate the fully connected layer operation |
It is worthwhile to point out a few things. First, the following two commands seem to give the same values but are very different. The first is a complete tensor object that gives float values but is actually quantized, look at dtype, it is actually quint.8.
1 | int_model.fc(int_model.quant(sample_data)) |
The output of this is a truly a float tensor, it not only shows as float values (same as before) but contains no quantization information.
1 | int_model.dequant(int_model.fc(int_model.quant(sample_data))) |
Thus, in order to recreate a quantization operation from PyTorch in any embedded system you do not need to implement a de-quant layer. You can simply multiply and subtract zero points from your weight layers appropriately. Look for the long note inside the forward pass of the manually quantized model for more information.
A Word on PyTorch and Quantization
PyTorch’s display in the console is not always indicative of what is happening in the back end, this section should clear up some questions, you may have (since I had them). The fundamental unit of data that goes between layers in PyTorch is always a Tensor, that is always displayed as a float. This is fairly confusing since when we think of a vector/tensor as quantized we see all the data as integers. But PyTorch works differently, when a tensor is quantized it is still displayed as a float, but its quantized data type and quantization scheme to get to that data type is stored as additional attributes to the tensor object. Thus, do not be confused if you still see float values displayed, you must look at the dtype to get a clear understanding of what the values are. In order to view a quantized tensor as a int, you need to call int_repr() on the tensor object. Note, this throws an error if the tensor has not been quantized in the first place. Also, note that when PyTorch encounters a quantized tensor, it will carry out multiplication on the quantized values automatically and thus the benefits of quantization will be realized even if you do not actually see them. When exporting the model this information is packaged as well, no need for anything extra to be done.
A Word on Quant and DeQuant Stubs
This is perhaps the most confusing of all things about quantization in PyTorch, the QuantStub and DeQuantStub.
- The job of de-quantizing something is automatically taken care of by the previous layer, as mentioned above. Thus when you come to a DeQuant Layer all it seems to do is just strip away the memory of having ever been quantized and ensures that the floating point representation is used. That is what is meant by the statement “DeQuantStub is stateless”, it literally needs nothing to function, all the information it needs to function will be packaged with the input tensor you feed into it.
- The Quant Stub, on the other hand, is stateful it needs to know the scale and the zero point of what is being fed into it, and the network has no knowledge of the input data, which is why you need to feed data into the Neural Network to get this going, if you knew the scale and zero point of your data already you could directly input that information into the QuantStub.
- The QuantStub and DeQuantStub are not actually layers, they are just functions that are called when the model is quantized.
- Another huge misconception is when and where to call these layers, every example on the PyTorch repo will have the Quant and DeQuant stub sandwiching the entire network, this leads people to think that the entire network is quantized. This is not true see the following section for more information.
Do you need to insert a Quant and DeQuant Stub after every layer in your model?
Unless you know exactly what you are doing, then YES you do. In most cases, especially for first time users, you usually want to dequantize immediately after quantizing. If you want to “quantize” every multiplication operation but dequantize the result (i.e. try to bring it back to your original scale of data) then yes, you do. The Quant and DeQuant Stub is “dumb” in the sense that it does not know what the previous layer was, if you feed it a quantized tensor it dequantizes it. It has no view of your network as a whole and does not modify the behavior of the network as a whole. Recall the mathematics of what we are trying to do. We want to replace a matrix multiplication,
Your first layer weights are
When do you not need to put Quant and DeQuant Stubs after every layer?
Dequantizing comes with a cost, you need to compute
Conclusion
In this blog post we covered some important details about PyTorch’s implementation of quantization that are not immediately obvious. We then went on to manually implement a quantized layer and a quantized model. We then showed how to use the quantized layer and the quantized model to get the same results as the PyTorch quantized model. We also showed that the PyTorch quantized model is not actually quantized in the sense that the values are integers, but that the values are quantized in the sense that the values are stored as tensor objects (that store their quantization parameters with them) and the operations are carried out on the integers. This is a very important distinction to make. Additionally, in inference mode, you can just take out the quantized weights, and skip the fc layer step as well, you can just multiply the two matrices together. This is what I will be doing in the embedded system case. In my next posts, I will show you how to quantize a model and the physics behind why multiplying two floats is more expensive than multiplying a two integers.