Are Values Passed Between Layers Float or Int in PyTorch Post Quantization?
Introduction
A common question I had when I first started working with quantization was, how exactly are values passed between layers post quantization? Looking at the quantization equations it was not immediately obvious to me how to do away with ALL floating point operations and what values were used exactly in the forward pass operation.
In this article, I will address two main questions,
- How does PyTorch pass values between layers post quantization? And what are the quantization equations used.
- What exactly makes floating point operations slower than integer operations?
In short, PyTorch passes integer values between layers when in INT8 only quantization. It does so using a few neat tricks of fixed point and floating point math. When in other quantization modes, values passed between layers can be float.
Quantized Matrix Multiplication
The overall goal of quantization is to make this multiplication operation simpler in some sense,
Carry out the multiplication operation in integers, as of now
are floats save
as an integers
We can achieve both ends by,
replacing
by adding subtracting terms to get back the original value
We can use the well known quantization scheme to carry out the quantization for each of these objects. As a recap, they are outlined again below. Personally, I just took these functions as given and “magically” converted between integers and floats, it is not quite that important to understand their inner workings at this stage. Using the quantization scheme,
We can write the above multiplication as,
Bias tends to be more important for accuracy than weights do, so it is in fact better if its higher in accuracy
Even though they are bigger than they need to be they account for a fraction of the parameters of the neural network.
Data Types Passed Between Layers
Using the matrix multiplication example before,
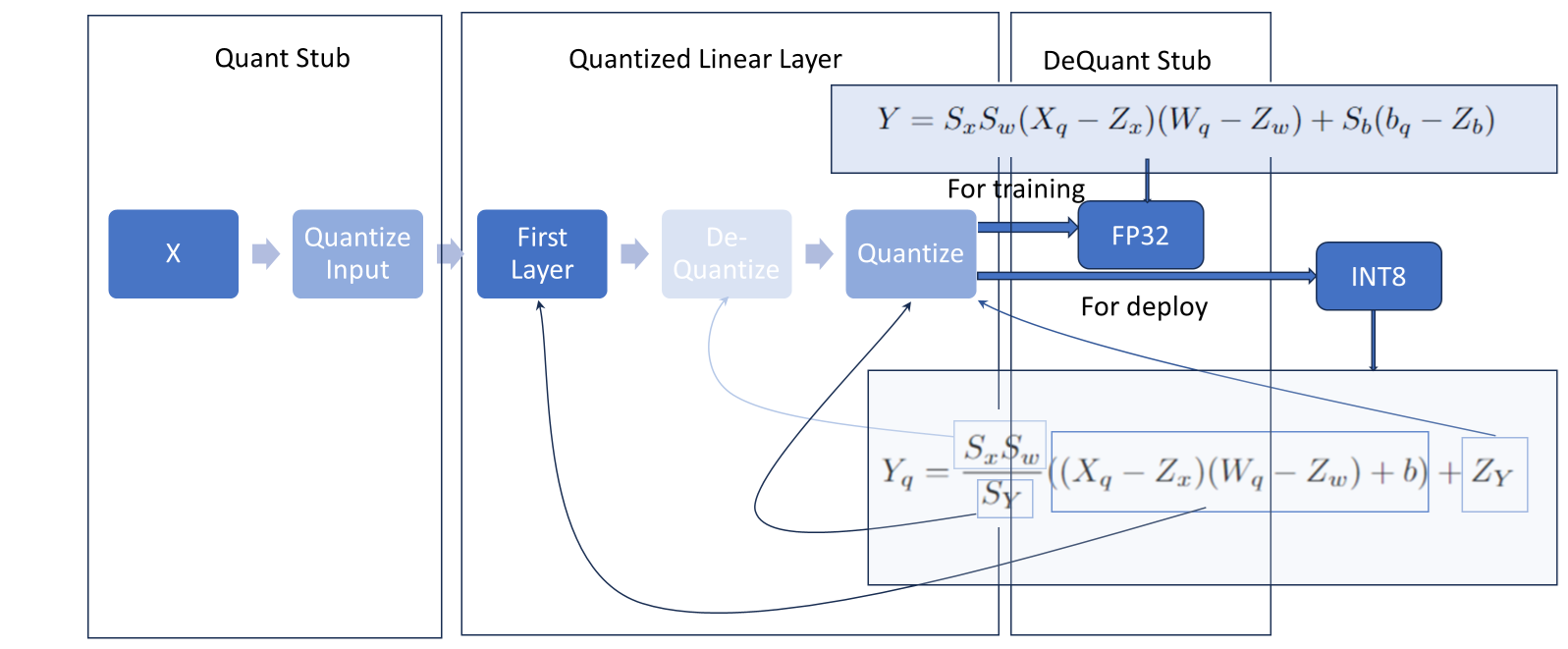
To summarize,
For full INT8 quantization i.e. when the embedded device does not support any floating point multiplies use
For partial INT8 quantization i.e. you want the activations to be in float but weights and integer multiplies to be done in/ saved as INT8 use the equation for
.
Why Exactly Does Floating Point Slow Things Down?
Another paint point for me was the lack of reasoning as to why multiplying two floating point numbers together takes longer/ is more difficult than multiplying two INTs together. The reason has to do with physics, and we will come to it in a minute. For now let us consider two floating point numbers and their resulting multiplication. Recall, that a floating point number is always of the form
Consider,
Add, the exponents
Multiply, the mantissas
Re-normalize, by dividing by
, exponent is now , mantissa is 1.00011 Sign, here both numbers are positive so the sign bit is
Truncate,
As you can see, multiplying two floating point numbers takes quite a bit of steps. In particular, re-normalization could potentially take multiple steps.
For contrast, consider a fixed point multiplication,
Add, exponents
Multiply, the mantissas 0.100011
Re-normalize,
Sign, here both numbers are positive so the sign bit is
Even though the re-normalization stage seems the same, it is actually always the same number of steps, whereas for the floating point case it can be arbitrarily long and needs to check whether there is a leading
pandoc version 3.2
Conclusion
In this article, we discussed how values are passed between layers post quantization in PyTorch. We also discussed why floating point operations are slower than integer operations. I hope this article was helpful in understanding the inner workings of quantization and the differences between floating point and integer operations. Again, PyTorch makes things very simple by doing things for you but if you need to understand the underlying concepts then you need to open things up and verify.
References
https://arxiv.org/pdf/1712.05877
https://arxiv.org/pdf/1806.08342