Bayesian Statistics : A/B Testing, Thompson sampling of multi-armed bandits, Recommendation Engines and more from Big Consulting
A friend of mine recently asked me for advice in preparing for an interview that required Bayesian statistics in Consulting. They asked me if I had done anything in Bayesian statistics. I decided to compile a list of representative projects that encapsulate the general idea of Bayesian statistics in consulting. These projects are rudimentary but could serve as a useful interview guide if needed!
Exploring Bayesian Methods: From A/B Testing to Recommendation Engines
Bayesian methods are like the secret sauce of data science. They add a layer of sophistication to measuring the success of machine learning (ML) algorithms and proving their effectiveness. In this post, I’ll walk you through how Bayesian statistics have shaped my approach to A/B testing and recommendation engines. Whether you’re a data science enthusiast or a seasoned pro, there’s something here for you!
Bayesian A/B Testing: A Real-World Example
Imagine you’re working on a project for a large telecommunications company, and your goal is to build a recommendation engine. This engine needs to send automated product recommendations to customers every 15 days. To test whether your new machine learning-based recommendations outperform the traditional heuristic approach, you decide to run an A/B test.
Measuring Success
In this scenario, we’re interested in measuring whether our recommendation engine performs better than the traditional method. We use a Bayesian approach to compare the click-through rates (CTR) of both methods. Click-through rate is a common metric that measures how often users click on the recommendations they receive.
We model the CTR using a beta distribution, which is parameterized by
1 | # Bayesian A/B Testing using Beta Distribution |
Choosing a Prior
Choosing the right prior for our Bayesian model was challenging. We had to match our new campaign against historical campaigns that were similar to ours and come up with appropriate values for
1 | # 4. Prior Distribution |
Updating Beliefs
Every 15 days, we collect new data and update our prior beliefs. The beta distribution is a conjugate prior, meaning its posterior distribution is also a beta distribution. Updating is straightforward:
This allows us to continuously refine our model as new data comes in.
1 | # 5. Likelihood and Posterior Distribution |
Simulating Results
To determine if our recommendation engine beats the traditional method, we simulate a pseudo p-value by drawing samples from the posterior. We check how often our recommendation engine outperforms the traditional one:
This tells us how frequently our engine’s CTR exceeds the traditional method’s CTR.
1 | # 6. Posterior Predictive Checks |
Conclusion
While complex measurement campaigns might signal trouble in some machine learning setups, our Bayesian approach showed promising results. Initially, our probability of outperforming the traditional method was 70%, which improved to 76%. This increase, combined with the ability to recommend high-margin products, demonstrated a tangible uplift due to our recommendation engine.
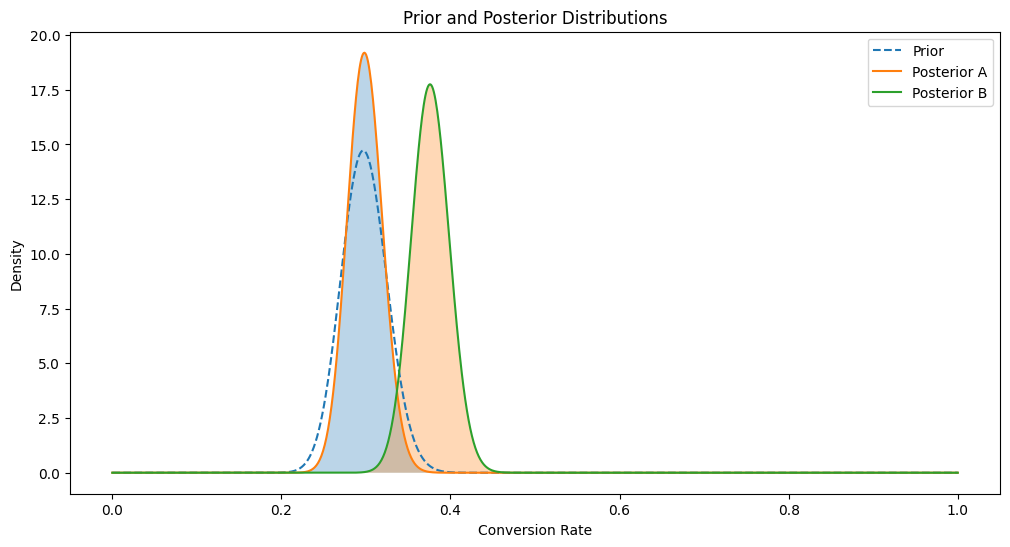
1 | # 8. Visualization |
Bayesian Recommendation Engines: Beyond A/B Testing
But Bayesian methods don’t stop at A/B testing. They also play a significant role in recommendation engines. Most of my work in consulting was in signal processing and recommendation engines. In many cases our clients did not even need very complex recommender systems, they could benefit from relatively simple Bayesian updation based on the users behavior.
Exploring the Power of Thompson Sampling for Multi-Armed Bandit Problems with Named Arms: A Deep Dive
Introduction
Imagine you’re running a bustling food delivery app, and you want to personalize the dining experience for your users. With an ever-growing list of restaurant options, how do you decide which cuisines to promote on the homepage? Should you highlight the new trendy Sushi place, the reliable Pizza joint, or the popular Chinese restaurant? Making the right choice can significantly impact user engagement and satisfaction.
Enter the world of multi-armed bandit problems—a fascinating realm of decision-making under uncertainty. In this blog post, we will explore how Thompson Sampling, a powerful Bayesian algorithm, can help us optimize our choices dynamically. We’ll dive into a practical implementation using named arms, representing different types of cuisine, to illustrate how this method can be a game-changer for your food delivery app.
The Multi-Armed Bandit Problem
The multi-armed bandit problem is a classic scenario in reinforcement learning and decision theory. Picture a row of slot machines (the “bandits”), each with an unknown payout probability. Your goal is to maximize your total reward by deciding which machine to play at each step. In our context, the “slot machines” are different types of cuisine, and the “payout” is the user’s engagement or order from that cuisine.
The challenge lies in balancing exploration (trying out different cuisines to learn their popularity) and exploitation (promoting the currently known most popular cuisine). Thompson Sampling provides an elegant solution to this exploration-exploitation dilemma by using Bayesian inference to update our beliefs about each cuisine’s popularity based on user interactions.
Why Thompson Sampling?
Thompson Sampling stands out for its simplicity and effectiveness. Unlike other methods that require complex calculations or large amounts of data, Thompson Sampling leverages probabilistic models to guide decision-making. By maintaining a distribution of potential outcomes for each option, it allows for a natural and intuitive way to balance exploration and exploitation.
Here’s how it works: for each cuisine, we maintain a Beta distribution representing our belief about its popularity. Each time a user makes an order, we update these distributions based on the observed data. When deciding which cuisine to promote next, we sample from these distributions and choose the one with the highest sampled value. This approach ensures that we are more likely to promote cuisines with higher expected rewards while still occasionally exploring less popular options to refine our estimates.
Practical Implementation
Let’s dive into a practical example. We’ll use three named arms—Chinese, Pizza, and Sushi—to demonstrate how Thompson Sampling can dynamically optimize our homepage recommendations. We’ll start with an initial belief about the popularity of each cuisine and update these beliefs as users interact with the app.
Initialization
We begin by setting up initial Beta distributions for each cuisine based on our prior knowledge or assumptions. For instance, if we believe Pizza is initially more popular, we can set higher alpha and beta parameters for its distribution.
1 | import numpy as np |
User Interaction Simulation
We simulate user interactions over a series of trials, where each interaction represents a user choosing a cuisine. Based on the observed choices, we update our Beta distributions to reflect the new data.
1 | # Simulate user interactions |
Posterior Analysis
After a number of interactions, we analyze the posterior distributions to determine which cuisine is likely to be popular. We can then use this information to sort and display the cuisines on our app’s homepage.
1 | # Sort arms based on the highest posterior mean |
Visualizing the Results
To make our analysis more intuitive, we plot the prior and the posterior distributions for each cuisine. These visualizations help us understand how our beliefs evolve over time and provide a clear picture of the most likely user preferences.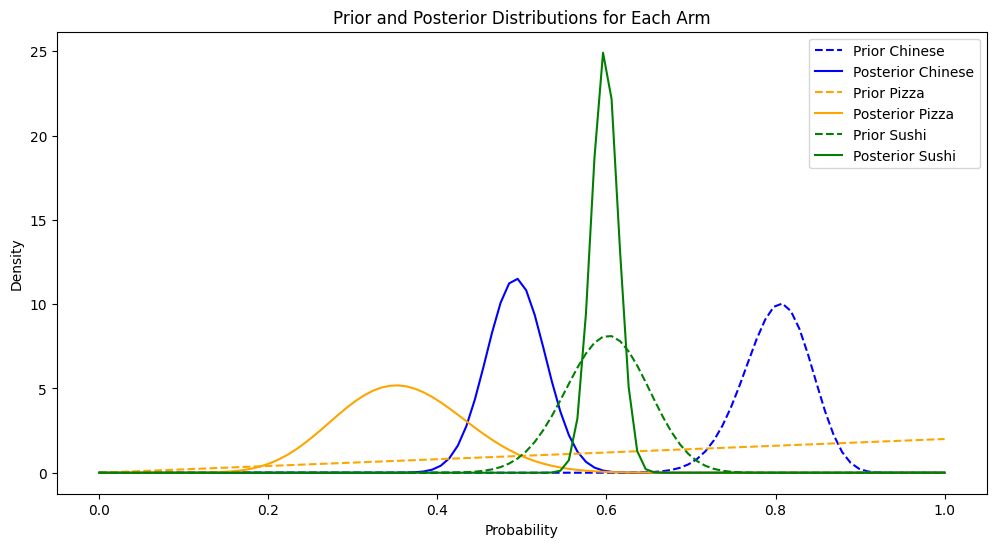
1 | # Function to plot both prior and posterior distributions |
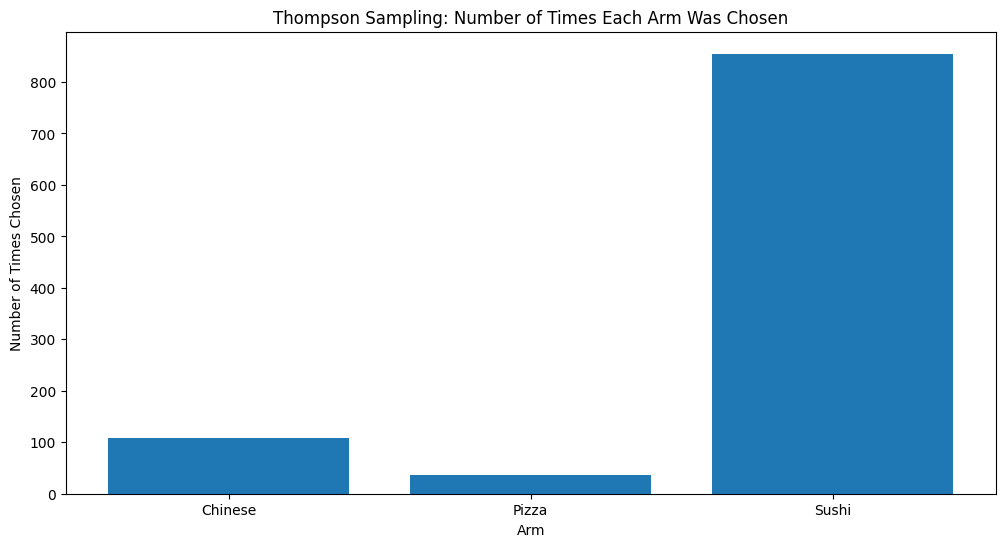
Through this implementation, we can see how Thompson Sampling dynamically adapts to user behavior, continually refining our recommendations to maximize user satisfaction.
Final Thoughts on Thompson Sampling
Thompson Sampling offers a powerful, flexible approach to solving the multi-armed bandit problem, particularly in dynamic and uncertain environments like a food delivery app. By leveraging Bayesian inference, it enables us to make data-driven decisions that balance exploration and exploitation effectively. Whether you are managing a food app, an e-commerce platform, or any other recommendation system, Thompson Sampling can help you optimize user engagement and drive better outcomes. So the next time you are faced with the challenge of deciding which options to promote, think of Thompson sampling!
Bayesian Matrix Factorization with Side Information
Bayesian Matrix Factorization (BMF) with side information is a powerful extension of traditional matrix factorization. It incorporates additional context about users and items to improve recommendations. Here’s a breakdown:
Likelihood Function
The likelihood function models the probability of observing user-item interactions given latent factors:
where
Prior Distributions
We assume Gaussian prior distributions for the latent factors:
Incorporating Side Information
Side information about users and items is integrated by conditioning the prior distributions:
Posterior Distribution
The posterior distribution of the latent factors given the observed data and side information is derived using Bayes’ theorem:
Approximate inference methods like Variational Inference or MCMC are used to estimate these factors.
Main Equation Summary
The core Bayesian matrix factorization model with side information can be summarized as:
This model integrates additional context into the matrix factorization process, enhancing the accuracy and robustness of the recommendation system.
Conclusion
Bayesian methods offer a versatile toolkit for data scientists, enhancing both A/B testing and recommendation engines. As computational constraints lessen, Bayesian approaches are gaining traction. I’m always eager to explore new use cases and dive deeper into the specifics of applying these methods in different scenarios. If you have a challenging problem or an interesting use case, I’d love to hear about it!
References
[Great Stanford tutorial on Thompson sampling] (https://web.stanford.edu/~bvr/pubs/TS_Tutorial.pdf)
[YouTube Video that formed the basis of my example] (https://www.youtube.com/watch?v=nRLI_KbvZTQ&t=321s)
[Overview of bandits] (https://eugeneyan.com/writing/bandits/)
[Contextual Bandits] (https://gdmarmerola.github.io/ts-for-contextual-bandits/)
[Bayesian Matrix Factorization] (https://www.cs.toronto.edu/~amnih/papers/bpmf.pdf)