Part III : What does Low Rank Factorization of a Convolutional Layer really do?
Decomposition of a Convolutional layer
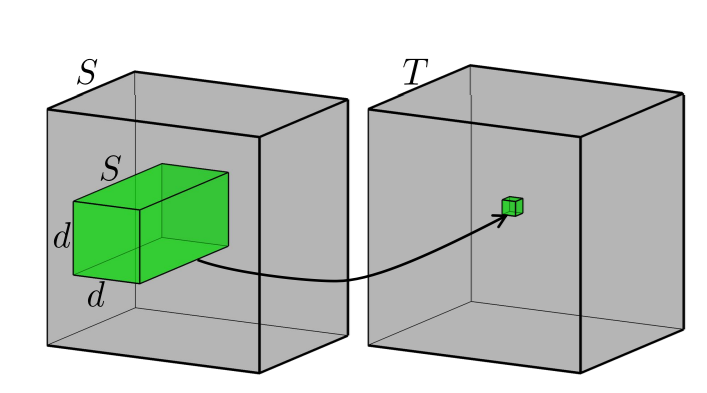
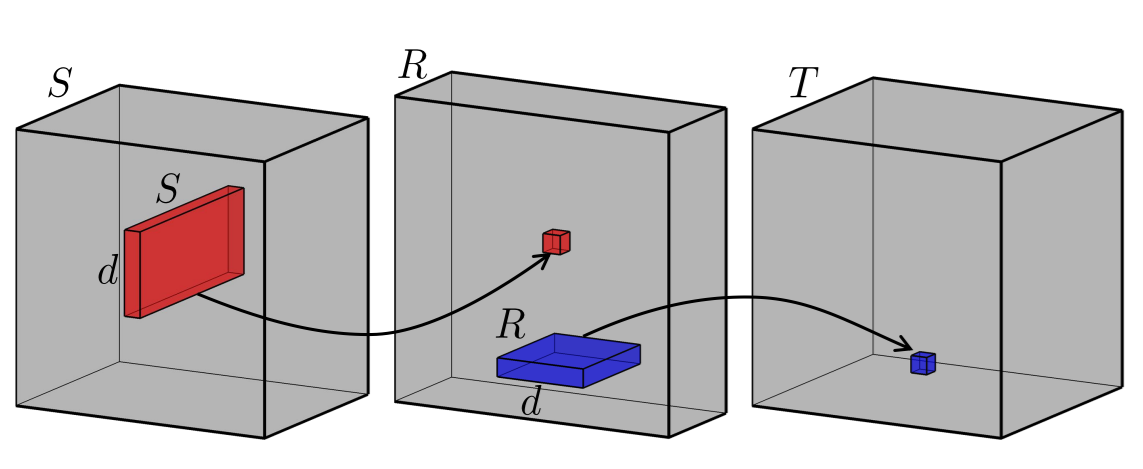
In a previous post I described (in some detail) what it means to decompose a matrix multiply into a sequence of low rank matrix multiplies. We can do something similar for a tensor as well, this is somewhat less easy to see since tensors (particularly in higher dimensions) are quite hard to visualize. Recall, the matrix formulation, Where and are the left and right singular vectors of respectively. The idea is to approximate as a sum of outer products of and of lower rank. Now instead of a weight matrix multiplication we have a kernel operation, where is the convolution operation. The idea is to approximate as a sum of outer products of and of lower rank. Interestingly, you can also think about this as a matrix multiplication, by creating a Toplitz matrix version of , call it and then doing . But this comes with issues as is much much bigger than . So we just approach it as a convolution operation for now.
Convolution Operation
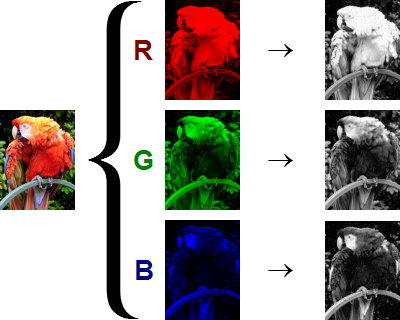
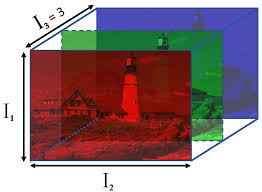
At the heart of it, a convolution operation takes a smaller cube subset of a “cube” of numbers (also known as the map stack) multiplies each of those numbers by a fixed set of numbers (also known as the kernel) and gives a single scalar output. Let us start with what each “slice” of the cube really represents.
Now that we have a working example of the representation, let us try to visualize what a convolution is.
A convolution operation takes a subset of the RGB image across all channels and maps it to one number (a scalar), by multiplying the cube of numbers with a fixed set of numbers (a.k.a kernel, not pictured here) and adding them together.A convolution operation multiplies each pixel in the image across all channels with a fixed number and add it all up.
Low Rank Approximation of Convolution
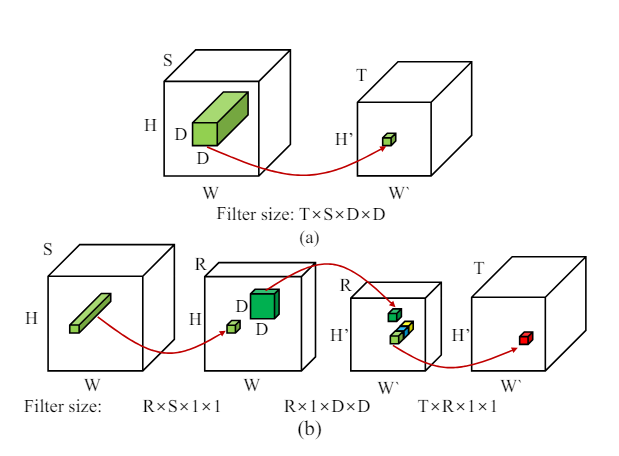
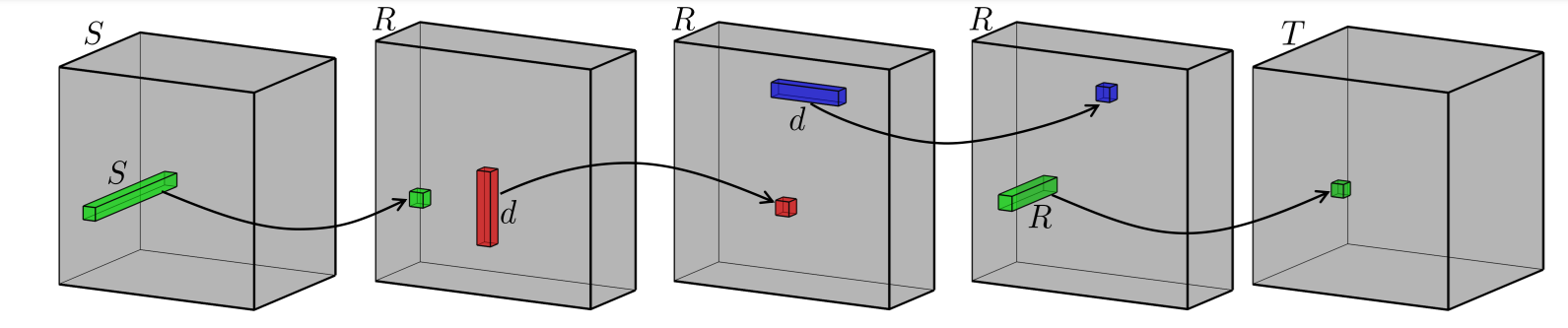
Now that we have a good idea of what a convolution looks like, we can now try to visualize what a low rank approximation to a convolution might look like. The particular kind of approximation we have chosen here does the following 4 operations to approximate the one convolution operation being done.
Painful Example of Convolution by hand
Consider the input matrix :
Input slice:
Kernel:
Element-wise multiplication and sum:
Now repeat that by moving the kernel one step over (you can in fact change this with the stride argument for convolution).
Low Rank Approximation of convolution
Now we will painfully do a low rank decomposition of the convolution kernel above. There is a theorem that says that a matrix can be approximated by a sum of 2 outer products of two vectors. Say we can express as,
We can easily guess . Consider,
This is easy because I chose values for the kernel that were easy to break down. How to perform this breakdown is the subject of the later sections.
Consider the original kernel matrix and the low-rank vectors:
The input matrix is:
Convolution with Original Kernel
Perform the convolution at the top-left corner of the input matrix:
Convolution with Low-Rank Vectors
Using the low-rank vectors:
Step 1: Apply (filter along the columns):**
Step 2: Apply (sum along the rows):**
Comparison
Convolution with Original Kernel: -2
Convolution with Low-Rank Vectors: 0
The results are different due to the simplifications made by the low-rank approximation. But this is part of the problem that we need to optimize for when picking low rank approximations. In practice, we will ALWAYS lose some accuracy
PyTorch Implementation
Below you can find the original definition of AlexNet.
defforward(self,x): x = self.layers['pool'](F.relu(self.layers['conv1'](x))) x = self.layers['pool'](F.relu(self.layers['conv2'](x))) x = torch.flatten(x, 1) x = F.relu(self.layers['fc1'](x)) x = F.relu(self.layers['fc2'](x)) x = self.layers['fc3'](x) return x
defevaluate_model(net): import torchvision.transforms as transforms batch_size = 4# [4, 3, 32, 32] transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') trainset = torchvision.datasets.CIFAR10(root='../data', train=True, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2) testset = torchvision.datasets.CIFAR10(root='../data', train=False, download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2) # prepare to count predictions for each class correct_pred = {classname: 0for classname in classes} total_pred = {classname: 0for classname in classes} # again no gradients needed with torch.no_grad(): for data in testloader: images, labels = data outputs = net(images) _, predictions = torch.max(outputs, 1) # collect the correct predictions for each class for label, prediction inzip(labels, predictions): if label == prediction: correct_pred[classes[label]] += 1 total_pred[classes[label]] += 1 # print accuracy for each class for classname, correct_count in correct_pred.items(): accuracy = 100 * float(correct_count) / total_pred[classname] print(f'Original Accuracy for class: {classname:5s} is {accuracy:.1f} %')
Now let us decompose the first convolutional layer into 3 simpler layers using SVD
defslice_wise_svd(tensor,rank): # tensor is a 4D tensor # rank is the target rank # returns a list of 4D tensors # each tensor is a slice of the input tensor # each slice is decomposed using SVD # and the decomposition is used to approximate the slice # the approximated slice is returned as a 4D tensor # the list of approximated slices is returned num_filters, input_channels, kernel_width, kernel_height = tensor.shape kernel_U = torch.zeros((num_filters, input_channels,kernel_height,rank)) kernel_S = torch.zeros((input_channels,num_filters,rank,rank)) kernel_V = torch.zeros((num_filters,input_channels,rank,kernel_width)) approximated_slices = [] reconstructed_tensor = torch.zeros_like(tensor) for i inrange(num_filters): for j inrange(input_channels): U, S, V = torch.svd(tensor[i, j,:,:]) U = U[:,:rank] S = S[:rank] V = V[:,:rank] kernel_U[i,j,:,:] = U kernel_S[j,i,:,:] = torch.diag(S) kernel_V[i,j,:,:] = torch.transpose(V,0,1)
# print the reconstruction error print("Reconstruction error: ",torch.norm(reconstructed_tensor-tensor).item())
return kernel_U, kernel_S, kernel_V
defsvd_decomposition_conv_layer(layer, rank): """ Gets a conv layer and a target rank, returns a nn.Sequential object with the decomposition """
# set weights as the svd decomposition U_layer.weight.data = kernel_U S_layer.weight.data = kernel_S V_layer.weight.data = kernel_V
return [U_layer, S_layer, V_layer] classlowRankNetSVD(Net): def__init__(self, original_network): super().__init__() self.layers = nn.ModuleDict() self.initialize_layers(original_network) definitialize_layers(self, original_network): # Make deep copy of the original network so that it doesn't get modified og_network = copy.deepcopy(original_network) # Getting first layer from the original network layer_to_replace = "conv1" # Remove the first layer for i, layer inenumerate(og_network.layers): if layer == layer_to_replace: # decompose that layer rank = 1 kernel = og_network.layers[layer].weight.data decomp_layers = svd_decomposition_conv_layer(og_network.layers[layer], rank) for j, decomp_layer inenumerate(decomp_layers): self.layers[layer + f"_{j}"] = decomp_layer else: self.layers[layer] = og_network.layers[layer] defforward(self, x): x = self.layers['conv1_0'](x) x = self.layers['conv1_1'](x) x = self.layers['conv1_2'](x) x = self.layers['pool'](F.relu(x)) x = self.layers['pool'](F.relu(self.layers['conv2'](x))) x = torch.flatten(x, 1) x = F.relu(self.layers['fc1'](x)) x = F.relu(self.layers['fc2'](x)) x = self.layers['fc3'](x) return x
Decomposition into a list of simpler operations
The examples above are quite simple and are perfectly good for simplifying neural networks. This is still an active area of research. One of the things that researchers try to do is try to further simplify each already simplified operation, of course you pay the price of more operations. The one we will use for this example is one where the operations is broken down into four simpler operations.
(Green) Takes one pixel from the image across all channels and maps it to one value
(Red) Takes one long set of pixels from one channel and maps it to one value
(Blue) Takes one wide set of pixels from one channel and maps it to one value
(Green) takes one pixel from all channels and maps it to one value
Intuitively, we are still taking the subset “cube” but we have broken it down so that in any given operation only dimension is not . This is really the key to reducing the complexity of the initial convolution operation, because even though there are more such operations each operations is more complex.
PyTorch Implementation
In this section, we will take AlexNet (Net), evaluate (evaluate_model) it on some data and then decompose the convolutional layers.
Declaring both the original and low rank network
Here we will decompose the second convolutional layer, given by the layer_to_replace argument. The two important lines to pay attention to are est_rank and cp_decomposition_conv_layer. The first function estimates the rank of the convolutional layer and the second function decomposes the convolutional layer into a list of simpler operations.
definitialize_layers(self, original_network): # Make deep copy of the original network so that it doesn't get modified og_network = copy.deepcopy(original_network) # Getting first layer from the original network layer_to_replace = "conv2" # Remove the first layer for i, layer inenumerate(og_network.layers): if layer == layer_to_replace: # decompose that layer rank = est_rank(og_network.layers[layer]) decomp_layers = cp_decomposition_conv_layer(og_network.layers[layer], rank) for j, decomp_layer inenumerate(decomp_layers): self.layers[layer + f"_{j}"] = decomp_layer else: self.layers[layer] = og_network.layers[layer] # Add the decomposed layers at the position of the deleted layer
defforward(self, x, layer_to_replace="conv2"): x = self.layers['pool'](F.relu(self.layers['conv1'](x))) # x = self.layers['pool'](F.relu(self.laye['conv2'](x) x = self.layers['conv2_0'](x) x = self.layers['conv2_1'](x) x = self.layers['conv2_2'](x) x = self.layers['pool'](F.relu(self.layers['conv2_3'](x))) x = torch.flatten(x, 1) x = F.relu(self.layers['fc1'](x)) x = F.relu(self.layers['fc2'](x)) x = self.layers['fc3'](x) return x
Evaluate the Model
You can evaluate the model by running the following code. This will print the accuracy of the original model and the low rank model.
decomp_alexnet = lowRankNetSVD(net) # replicate with original model
correct_pred = {classname: 0for classname in classes} total_pred = {classname: 0for classname in classes}
# again no gradients needed with torch.no_grad(): for data in testloader: images, labels = data outputs = decomp_alexnet(images) _, predictions = torch.max(outputs, 1) # collect the correct predictions for each class for label, prediction inzip(labels, predictions): if label == prediction: correct_pred[classes[label]] += 1 total_pred[classes[label]] += 1
# print accuracy for each class for classname, correct_count in correct_pred.items(): accuracy = 100 * float(correct_count) / total_pred[classname] print(f'Lite Accuracy for class: {classname:5s} is {accuracy:.1f} %')
Let us first discuss estimate rank. For a complete discussion see the the references by Nakajima and Shinchi. The basic idea is that we take the tensor, “unfold” it along one axis (basically reduce the tensor into a matrix by collapsing around other axes) and estimate the rank of that matrix. You can find est_rank below.
from __future__ import division import torch import numpy as np # from scipy.sparse.linalg import svds from scipy.optimize import minimize_scalar import tensorly as tl
defest_rank(layer): W = layer.weight.data # W = W.detach().numpy() #the weight has to be a numpy array for tl but needs to be a torch tensor for EVBMF mode3 = tl.base.unfold(W.detach().numpy(), 0) mode4 = tl.base.unfold(W.detach().numpy(), 1) diag_0 = EVBMF(torch.tensor(mode3)) diag_1 = EVBMF(torch.tensor(mode4))
# round to multiples of 16 multiples_of = 8# this is done mostly to standardize the rank to a standard set of numbers, so that # you do not end up with ranks 7, 9 etc. those would both be approximated to 8. # that way you get a sense of the magnitude of ranks across multiple runs and neural networks # return int(np.ceil(max([diag_0.shape[0], diag_1.shape[0]]) / 16) * 16) returnint(np.ceil(max([diag_0.shape[0], diag_1.shape[0]]) / multiples_of) * multiples_of)
defEVBMF(Y, sigma2=None, H=None): """Implementation of the analytical solution to Empirical Variational Bayes Matrix Factorization. This function can be used to calculate the analytical solution to empirical VBMF. This is based on the paper and MatLab code by Nakajima et al.: "Global analytic solution of fully-observed variational Bayesian matrix factorization." Notes ----- If sigma2 is unspecified, it is estimated by minimizing the free energy. If H is unspecified, it is set to the smallest of the sides of the input Y. Attributes ---------- Y : numpy-array Input matrix that is to be factorized. Y has shape (L,M), where L<=M. sigma2 : int or None (default=None) Variance of the noise on Y. H : int or None (default = None) Maximum rank of the factorized matrices. Returns ------- U : numpy-array Left-singular vectors. S : numpy-array Diagonal matrix of singular values. V : numpy-array Right-singular vectors. post : dictionary Dictionary containing the computed posterior values. References ---------- .. [1] Nakajima, Shinichi, et al. "Global analytic solution of fully-observed variational Bayesian matrix factorization." Journal of Machine Learning Research 14.Jan (2013): 1-37. .. [2] Nakajima, Shinichi, et al. "Perfect dimensionality recovery by variational Bayesian PCA." Advances in Neural Information Processing Systems. 2012. """ L, M = Y.shape # has to be L<=M
if H isNone: H = L
alpha = L / M tauubar = 2.5129 * np.sqrt(alpha)
# SVD of the input matrix, max rank of H U, s, V = torch.svd(Y) U = U[:, :H] s = s[:H] V[:H].t_()
# Calculate residual residual = 0. if H < L: residual = torch.sum(torch.sum(Y ** 2) - torch.sum(s ** 2))
# Formula (15) from [2] d = torch.mul(s[:pos] / 2, 1 - (L + M) * sigma2 / s[:pos] ** 2 + torch.sqrt( (1 - ((L + M) * sigma2) / s[:pos] ** 2) ** 2 - \ (4 * L * M * sigma2 ** 2) / s[:pos] ** 4))
return torch.diag(d)
You can find the EVBMF code on my github page. I do not go into it in detail here. Jacob Gildenblatt’s code is a great resource for an in-depth look at this algorithm.
Conclusion
So why is all this needed? The main reason is that we can reduce the number of operations needed to perform a convolution. This is particularly important in embedded systems where the number of operations is a hard constraint. The other reason is that we can reduce the number of parameters in a neural network, which can help with overfitting. The final reason is that we can reduce the amount of memory needed to store the neural network. This is particularly important in mobile devices where memory is a hard constraint. What does this mean mathematically? Fundamentally it means that neural networks are over parameterized i.e. they have far more parameters than the information that they represent. By reducing the rank of the matrices needed carry out a convolution, we are representing the same operation (as closely as possible) with a lot less information.