Unifying Tensor Factorization and Graph Neural Networks: Review of Mathematical Essentials for Recommender Systems
Introduction
When do I use “old-school” ML models like matrix factorization and when do I use graph neural networks?
Can we do something better than matrix factorization?
Why can’t we use neural networks? What is matrix factorization anyway?
These are just some of the questions, I get asked whenever I start a recommendation engine project. Answering these questions requires a good understanding of both algorithms, which I will try to outline here. The usual way to understand the benefit of one algorithm over the other is by trying to prove that one is a special case of the other.
While it can be shown that a Graph Neural Network can be expressed as a matrix factorization problem. This matrix is not easy to interpret in the usual sense. Contrary to popular belief, matrix factorization (MF) is not “simpler” than a Graph Neural Network (nor is the opposite true). To make matters worse, the GCN is actually more expensive to train since it takes far more cloud compute than does MF. The goal of this article is to provide some intuition as to when a GCN might be worthwhile to try out.
This article is primarily aimed at data science managers with some background in linear algebra (or not, see next sentence) who may or may not have used a recommendation engine package before. Having said that, if you are not comfortable with some proofs I have a key takeaways subsection in each section that should form a good basis for decision making that perhaps other team members can dig deep into.
Key Tenets of Linear Algebra and Graphs in Recommendation Engine design
The key tenets of design come down to the difference between a graph and a matrix. The linking between graph theory and linear algebra comes from the fact that ALL graphs come with an adjacency matrix. More complex versions of this matrix (degree matrix, random walk graphs) capture more complex properties of the graph. Thus you can usually express any theorem in graph theory in matrix form by use of the appropriate matrix.
- The Matrix Factorization of the interaction matrix (defined below) is the most commonly used form of matrix factorization. Since this matrix is the easiest to interpret.
- Any Graph Convolutional Neural Network can be expressed as the factorization of some matrix, this matrix is usually far removed from the interaction matrix and is complex to interpret.
- For a given matrix to be factorized, matrix factorization requires fewer parameters and is therefore easier to train.
- Graphical structures are easily interpretable even if matrices expressing their behavior are not.
Tensor Based Methods
In this section, I will formulate the recommendation engine problem as a large tensor or matrix that needs to be “factorized”.
In one of my largest projects in Consulting, I spearheaded the creation of a recommendation engine for a top 5 US retailer. This project presented a unique challenge: the scale of the data we were working with was staggering. The recommendation engine had to operate on a 3D tensor, made up of products × users × time. The sheer size of this tensor required us to think creatively about how to scale and optimize the algorithms.
Let us start with some definitions, assume we have
User latent features, given by matrix
of dimension and each index of this matrix is Products latent features, given by matrix
, of dimensions and each index of this matrix is Time latent features given by Matrix
, of dimensions and each index of this matrix is Interaction given by
in the tensor case, and in the matrix case. Usually this represents either purchasing decision, or a rating (which is why it is common to name this ) or a search term. I will use the generic term “interaction” to denote any of the above.
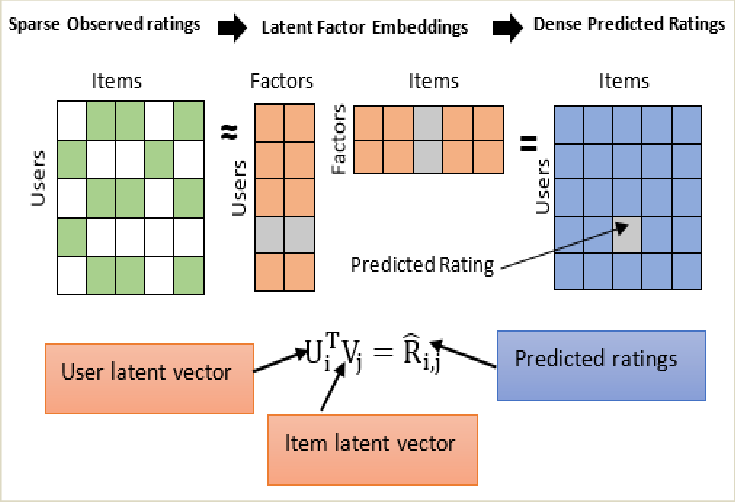
In the absence of a third dimension one could look at it as a matrix factorization problem, as shown in the image below,
Increasingly, however, it is important to take other factors into account when designing a recommendation system, such as context and time. This has led to the tensor case being the more usual case.
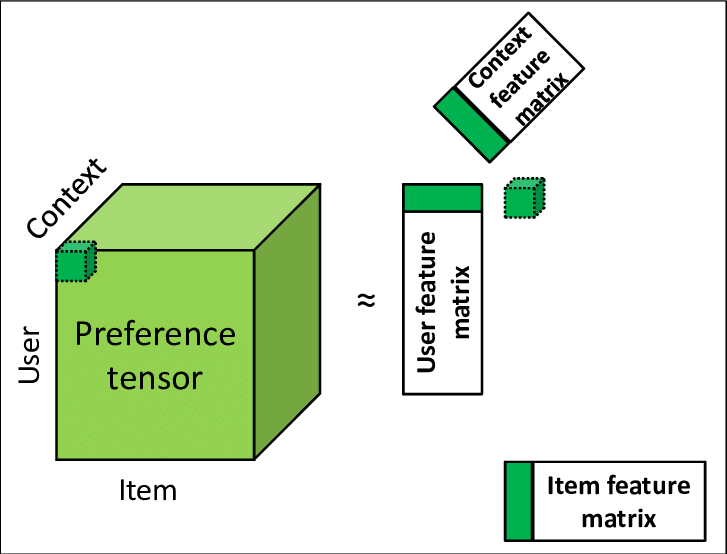
This means that for the
Side Information
Very often in a real word use case, our clients often have information that they are eager to use in a recommendation system. These range from user demographic data that they know from experience is important, to certain product attribute data that has been generated from a different machine learning algorithm. In such a case we can integrate that into the equation given above,
Where,
Optimization
We can then set up the following loss function,
Where:
and are regularization terms for the alignment with side information. controls the regularization of the latent matrices , , and . The first term is the reconstruction loss of the tensor, ensuring that the interaction between users, products, and time is well-represented.
The second and third terms align the latent factors with the side information for users and products, respectively.
Tensor Factorization Loop
For each iteration:
Compute the predicted tensor using the factorization:
Compute the loss using the updated loss function.
Perform gradient updates for
, , and . Regularize the alignment between
, with and Repeat until convergence.
Key Takeaway
Matrix factorization allows us to decompose a matrix into two low-rank matrices, which provide insights into the properties of users and items. These matrices, often called embeddings, either embed given side information or reveal latent information about users and items based on their interaction data. This is powerful because it creates a representation of user-item relationships from behavior alone.
In practice, these embeddings can be valuable beyond prediction. For example, clients often compare the user embedding matrix
Mathematically, the key takeaway is the following equation (at the risk of overusing a cliche, this is the
Multiplying the lower dimensional representation of the
Extensions
You do not need to stick to the simple multiplication in the objective function, you can do something more complex,
The above objective function is the LINE embedding. Where
Interaction Tensors as Graphs
One can immediately view a the interactions between users and items as a bipartite graph, where an edge is present only if the user interacts with that item. It is immediately obvious that we can embed the interactions matrix inside the adjacency matrix, noting that there are no edges between users and there are no edges between items.
The adjacency matrix
Recall, the matrix factorization
where:
is the user-item interaction matrix (binary values: 1 if a user has interacted with an item, 0 otherwise), is the transpose of , representing item-user interactions.
For example, if
Note, here that
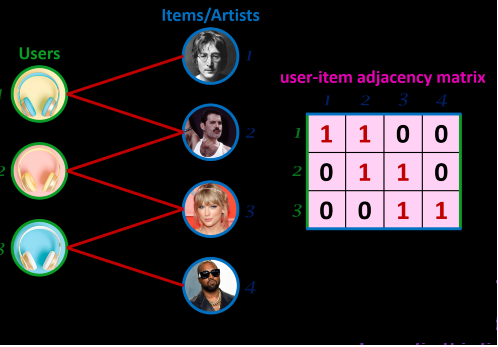
Matrix Factorization of Adjacency Matrix
Now you could use factorize,
What are the REAL Cons of Matrix Factorization
Matrix factorization offers key advantages in a consulting setting by quickly assessing the potential of more advanced methods on a dataset. If the user-item matrix performs well, it indicates useful latent user and item embeddings for predicting interactions. Additionally, regularization terms help estimate the impact of any side information provided by the client. The resulting embeddings, which include both interaction and side information, can be used by marketing teams for tasks like customer segmentation and churn reduction.
First, let me clarify some oft quoted misconceptions about matrix factorization disadvantages versus GCNs,
User item interactions are a simple dot product (
) and is therefore not linear. This is not true, even in the case of a GCN the final prediction is given by a simple dot product between the embeddings. Matrix factorization cannot use existing features . This is probably due to the fact that matrix factorization was popularized by the simple Netflix case, where only user-item matrix was specified. But in reality, very early in the development of matrix factorization, all kinds of additional regularization terms such as bias, side information etc. were introduced. The side information matrices are where you can specify existing features (recall,
). Cannot handle cold start Neither matrix factorization nor neural networks can handle the cold start problem very well. However, this is not an unfair criticism as the neural network is better, but this is more as a consequence of its truly revolutionary feature, which I will discuss under its true advantage.
Higher order interactions this is also false, but it is hard to see it mathematically. Let me outline a simple approach to integrate side information. Consider the matrix adjacency matrix
, gives you all edges with length , such that represents all nodes that are at most edges away. You can then factorize this matrix to get what you want. This is not an unfair criticism either as multiplying such a huge matrix together is not advised and neither is it the most intuitive method.
The biggest problem with MF is that a matrix is simply not a good representation of how people interact with products and each other. Finding a good mathematical representation of the problem is sometimes the first step in solving it. Most of the benefits of a graph convolutional neural network come as a direct consequence of using a graph structure not from the neural network architecture. The graph structure of a user-item behavior is the most general form of representation of the problem.
Complex Interactions - In this structure one can easily add edges between users and between products. Note in the matrix factorization case, this is not possible since
is only users x items. To include more complex interactions you pay the price with a larger and larger matrix. Graph Structure - Perhaps the most visually striking feature of graph neural networks is that they can leverage graph structure itself (see Figure 4). Matrix factorization cannot do so easily
Higher order interactions can be captured more intuitively than in the case of matrix factorization
Before implementing a GCN, it’s important to understand its potential benefits. In my experience, matrix factorization often provides good results quickly, and moving to GCNs makes sense only if matrix factorization has already shown promise. Another key factor is the size and richness of interactions. If the graph representation is primarily bipartite, adding user edges may not significantly enhance the recommender system. In retail, edges sometimes represented families, but these structures were often too small to be useful—giving different recommendations to family members like
I would be remiss, if I did not add that ALL of these issues with matrix factorization can be fixed by tweaking the factorization in some way. In fact, a recent paper Unifying Graph Convolutional Networks as Matrix Factorization by Liu et. al. does exactly this and shows that this approach is even better than a GCN. Which is why I think that the biggest advantage of the GCN is not that it is “better” in some sense, but rather the richness of the graphical structure lends itself naturally to the problem of recommending products, even if that graphical structure can then be shown to be equivalent to some rather more complex and less intuitive matrix structure. I recommend the following experiment flow :
A Simple GCN model
Let us continue on from our adjacency matrix
The second additive term bears a bit of explaining. Since the adjacency matrix has a
We need to make another important adjustment to
Here
Here we can split the equations by the subgraphs for which they apply to,
Note the equivalence the matrix case, in the matrix case we have to stack it ourselves because of the way we set up the matrix, but in the case of a GCN
The likelihood of an interaction is,
The loss function is,
We can substitute the components of
This is the main “result” of this blog post that you can equally look at this one layer GCN as a matrix factorization problem of the user-item interaction matrix but with the more complex looking low rank matrices on the right. In this sense, you can always create a matrix factorization that equates to the loss function of a GCN.
You can update parameters using SGD or some other technique. I will not get into that too much in this post.
Understanding the GCN equation
Equations 1 and 2 are the most important equations in the GCN framework.
More succinctly,
Equivalence to Matrix Factorization for a one layer GCN
You could just as easily have started with two random matrices
So you get the same outcome for a one layer GCN as you would from matrix factorization. Note that, it has been proved that even multi-layer GCNs are equivalent to matrix factorization but the matrix being factorized is not that easy to interpret.
Key Takeaways
The differences between MF and GCN really begin to take form when we go into multi-layerd GCNs. In the case of the one layer GCN the embeddings of
2 layer: every customer’s embedding is influenced by the embeddings of the products they consume and the embeddings of other customers of the products they consume. Similarly, every product is influenced by the customers who consume that product as well as by the products of the customers who consume that product.
3 layer: every customers embedding is influenced by the products they consume, other customers of the products they consume and products consumed by other customers of the products they consume. Similarly, every product is influenced by the consumers of that product, as well as products of consumers of that product as well as products consumed by consumers of that product.
You can see where this is going, in most practical applications, there are only so many levels you need to go to get a good result. In my experience
That leads to another critical point when considering GCNs, you really pay a price (in blood, mind you) for every layer deep you go. Consider the one layer case, you really have
Going the other way, if you are considering more than
Final Prayer and Blessing
I would like for the reader of this to leave with a better sense of the relationship between matrix factorization and GCNs. Like most neural network based models we tend to think of them as a black box and a black box that is “better”. However, in the one layer GCN case we can see that they are equal, with the GCN in fact having more learnable parameters (therefore more cost to train).
Therefore, it makes sense to use
How to go from MF to GCNs
Start with matrix factorization of the user-item matrix, maybe add in context or time. If it performs well and recommendations line up with non-ML recommendations (using base segmentation analysis), that means the model is at least somewhat sensible.
Consider doing a GCN next if the performance of MF is decent but not great. Additionally, definitely try GCN if you know (from marketing etc) that the richness of the graph structure actually plays a role in the prediction. For example, in the sale of Milwaukee tools a graph structure is probably not that useful. However, for selling Thursday Boots which is heavily influenced by social media clusters, the graph structure might be much more useful.
Interestingly, the MF matrices tend to be very long and narrow (there are usually thousands of users and most companies have far more users than they have products. This is not true for a company like Amazon (300 million users and 300 million products). But if you have a long narrow matrix that is sparse you are not too concerned with computation since at worst you have
, it does not matter much whether you do MF or GCN, but when , for such a case the matrix approach will probably give you a faster result.
It is worthwhile in a consulting environment to always start with a simple matrix factorization, the GCN for simplicity of use and understanding but then find a matrix structure that approximates only the most interesting and rich aspects of the graph structure that actually influence the final recommendations.
References
https://jonathan-hui.medium.com/graph-convolutional-networks-gcn-pooling-839184205692
https://tkipf.github.io/graph-convolutional-networks/ https://openreview.net/forum?id=HJxf53EtDr
https://distill.pub/2021/gnn-intro/ https://jonathan-hui.medium.com/graph-convolutional-networks-gcn-pooling-839184205692