Soft Actor Critic (Visualized) Part 2: Lunar Lander Example from Scratch in Torch
Introduction
Just like in the previous example using the CartPole environment, we will be using the Lunar Lander environment from OpenAI Gym. The goal of this example is to implement the Soft Actor Critic (SAC) algorithm from scratch using PyTorch. The SAC algorithm is a model-free, off-policy actor-critic algorithm that uses a stochastic policy and a value function to learn optimal policies in continuous action spaces.
Like before, I will be using notation that matches the original paper (Haarnoja et al., 2018) and the code will be structured in a similar way to the previous example. The main difference is that we will be using a different environment and a different algorithm.
Since the paper’s notation is critical to the understanding of the code, I highly recommend reading that alongside (or before) diving into the code.
Part 1 of this series provides extensive details linking the theory to the code. In this part, we will focus on the implementation of the SAC algorithm in PyTorch for Lunar Lander.
https://github.com/FranciscoRMendes/soft-actor-critic/blob/main/lunar-lander/LL_main_sac.py
Example Data
| Action | Reward | State | Done | Next State | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Main | Lateral | x | y | v_x | v_y | angle | angular velocity | left contact | right contact | x | y | v_x | v_y | angle | angular velocity | left contact | right contact | ||
| 0.66336113 | -0.485024 | -1.56 | 0.00716772 | 1.4093536 | 0.7259957 | -0.06963848 | -0.0082988 | -0.16444895 | 0 | 0 | False | 0.01442766 | 1.4081073 | 0.73378086 | -0.05545701 | -0.01600615 | -0.15416077 | 0 | 0 |
| 0.87302077 | 0.8565877 | -2.85810149 | 0.01442766 | 1.4081073 | 0.73378086 | -0.05545701 | -0.01600615 | -0.15416077 | 0 | 0 | False | 0.02185297 | 1.4071543 | 0.7518369 | -0.04247425 | -0.02521554 | -0.18420467 | 0 | 0 |
| 0.4880578 | 0.18216014 | -2.248854395 | 0.02185297 | 1.4071543 | 0.7518369 | -0.04247425 | -0.02521554 | -0.18420467 | 0 | 0 | False | 0.02941189 | 1.4065428 | 0.7646336 | -0.02735517 | -0.03385869 | -0.17287907 | 0 | 0 |
| 0.0541396 | -0.70224154 | -0.765160122 | 0.02941189 | 1.4065428 | 0.7646336 | -0.02735517 | -0.03385869 | -0.17287907 | 0 | 0 | False | 0.03697386 | 1.4056652 | 0.7634756 | -0.03918146 | -0.04105976 | -0.14403483 | 0 | 0 |
Lunar Lander Dataset Explanation
This dataset captures the experience of an agent in the Lunar Lander environment from OpenAI Gym. Each row represents a single transition (state, action, reward, next state) in the environment.
Environment Details
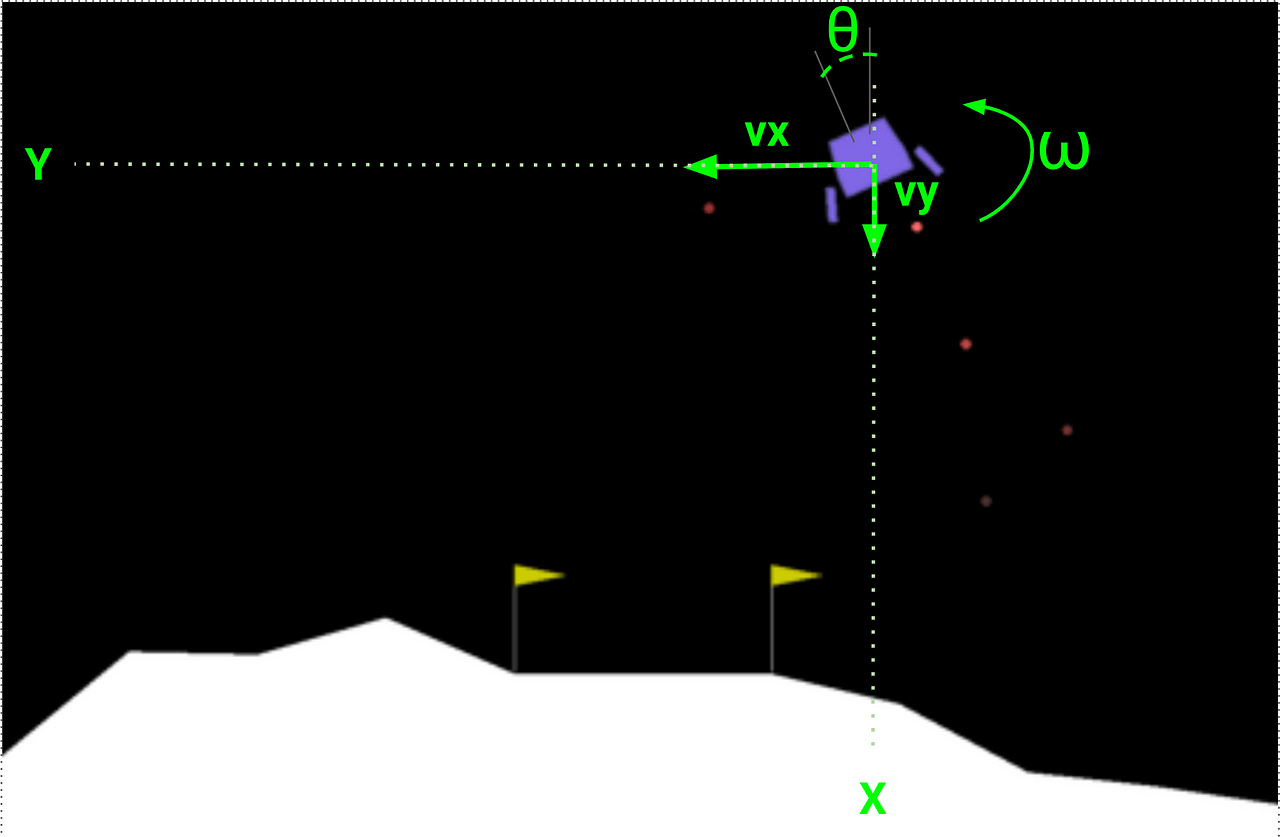
Action
Main Engine: The thrust applied to the main engine.Lateral Thruster: The thrust applied to the left/right thrusters.
Reward
- The reward received in this step. It is based on:
- Proximity to the landing pad.
- Smoothness of the landing.
- Fuel consumption.
- Avoiding crashes.
- The reward received in this step. It is based on:
State
x, y: Position coordinates.v_x, v_y: Velocity components.theta: The lander’s rotation angle.omega: The rate of change of the angle.left contact, right contact: Binary indicators (0 or 1) showing whether the lander has made contact with the ground.
Done
True: The episode has ended (either successful landing or crash).False: The episode is still ongoing.
Next State
- The same attributes as State, but after the action has been applied.
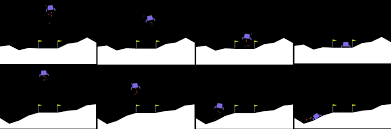
Sample Game Play
Game play 500 games
YouTube video embedded