Francisco Romaldo Fernandes MendesHexohttps://franciscormendes.github.io/gallery/favicon-32x32.pnghttps://franciscormendes.github.io/All rights reserved 2026, Francisco Romaldo Fernandes MendesFrancisco Mendes2026-04-10T16:42:50.520ZFrancisco Romaldo Fernandes Mendes
Bayesian A/B Testing Is Not Immune to Peeking: Insights from the AV Marketplace
The Setup
Imagine you are running an experiment to test the efficacy of a rewards program built to incentivize the use of autonomous vehicles in a ride-share marketplace. AVs cost more to operate than driver cars, so the business case depends heavily on whether riders can be nudged toward them at sufficient volume. The rewards program is the nudge — discounts, points, whatever it takes — and you need to know if it works.
The catch is that the rewards program itself costs money for every day it runs. Every subsidised ride is a line item. So there is real pressure to end the experiment as early as possible. Enter some Bayesian fanatic who proposes the solution: run a Bayesian experiment instead of a frequentist one. The argument is that Bayesian methods allow you to check results continuously and stop the moment you have sufficient evidence, which would dispense entirely with the need for a fixed sample size, the indignity of waiting, and crucially the problem of peeking.
The Bayesian in this comic is right about priors. The Bayesian in our meeting was right about priors too. Neither of them was right about the experiment being cheap.
My disagreement was vigorous enough that simply asserting it felt insufficient, and so I brought the math, which has the considerable advantage of being harder to dismiss than mere opinion.
Frequentist Sample Size
To set the baseline, here is the standard frequentist formulation. We are testing whether the rewards program (arm B) increases AV ride take-rate relative to no rewards (arm A), where $\theta$ is the probability a rider chooses an AV:
where $z_q$ denotes the $q$-th quantile of the standard normal distribution. The numerator grows with the variance of each arm; the denominator shrinks with the effect size squared. If the rewards program moves the AV take-rate only slightly, you need a very large experiment. This was, in fact, the source of the cost anxiety — the expected lift was small, which meant the required sample size was large, which meant the rewards program would run for a long time at a loss.
This is the formula the Bayesian fanatic wanted to escape. On to the proposed alternative.
Bayesian Sample Size
The Bayesian formulation replaces the frequentist error guarantees with a posterior expected loss criterion. We approximate the posterior on each arm’s conversion rate as Gaussian — reasonable for proportions with sufficient data:
where $\Phi^{-1}$ is the inverse standard normal CDF. Look at the structure. It is identical to the frequentist formula. The variance terms are the same. The effect size in the denominator is the same. The only difference is the squared prefactor: $\left[\Phi^{-1}(1-\epsilon)\right]^2$ instead of $\left(z_{1-\alpha/2} + z_{1-\beta}\right)^2$.
Example
Put some numbers on it. Suppose the baseline AV take-rate is 50% and the rewards program is expected to lift it by 2 percentage points:
On paper, the Bayesian approach needs roughly a third of the frequentist sample. If you are the person trying to minimise the cost of subsidising AV rides, this looks like exactly what you wanted, and it is the kind of result that tends to end conversations in rooms where people are more motivated by the cost of the experiment than the integrity of it. It is also, as it turns out, not quite right.
Bayesian Is Not Immune to Peeking
The critical assumption buried in the Bayesian sample size formula is that you collect $n_\text{bayes}$ samples and then evaluate the stopping criterion. You do not evaluate it after every ride. You do not check it at the end of each day because finance is asking. You do not peek.
Peeking is the practice of inspecting results before the planned sample size is reached and stopping early if the numbers look good. It is what invalidates frequentist tests when p-values are checked repeatedly mid-experiment — the false positive rate inflates because you are effectively running multiple tests and keeping the best result. The same logic applies to the Bayesian posterior.
Run enough tests, check often enough, and green jelly beans will cause acne. The Bayesian equivalent: check the posterior enough times and your rewards program will appear to work. The AV subsidy line item does not care which framework licensed your false positive.
If you evaluate $p_\text{wrong} < \epsilon$ continuously and stop the moment it dips below threshold, you have not run the experiment described by the formula above. You have run something different, with different — and worse — statistical properties. The Bayesian framing does not make this problem disappear. It reframes it. The stopping rule is still a rule, and it must be respected as such.
The Deeper Point
Now consider what happens when you align the frequentist and Bayesian parameters. Under a non-informative prior and Gaussian approximation:
The two formulas are identical. After one round of experimentation, you can always set $\hat{\theta}_A = \theta_A$ and the sample sizes converge exactly. The Bayesian framework is not buying you a smaller experiment — it is buying you a different interpretation of the same data collected over the same period, subsidising the same number of AV rides.
The cost of the rewards program does not go down because you chose a different statistical paradigm. The experiment still needs to run for exactly as long as the sample size demands, the rides still need to be subsidised for the duration of it, and the rewards program still costs the same amount of money regardless of what you call the statistical framework governing your decision.
If there is a genuine desire to reduce experiment duration, the honest levers are: a larger expected effect size (better rewards design), higher tolerance for error ($\epsilon$ or $\alpha$), or accepting lower power. Switching from frequentist to Bayesian and calling it done is not one of them.
]]>
https://franciscormendes.github.io/2026/04/10/bayesian-vs-frequentist-sample-size/2026-04-10T00:00:00.000ZA ride-share AV rewards program, a Bayesian fanatic, and the claim that Bayesian experiments let you peek. They do not. Here is the math.Bayesian A/B Testing Is Not Immune to Peeking: Insights from the AV Marketplace2026-04-10T16:42:50.520ZFrancisco Romaldo Fernandes MendesIntroduction
In autonomous driving, perception systems typically rely on photons i.e. cameras, lidar, and radar. But what if we could also listen to the environment, capturing sound cues that are invisible to traditional vision-based sensors?
There are many intuitively appealing use cases where an additional sensing modality could enhance awareness of the surroundings. Acoustic sensing itself is not new in automotive systems. For example, ultrasonic sensors have long been used for short-range applications such as parking assistance. Extending this idea to environmental sound sensing—allowing a vehicle to effectively hear its surroundings—has been explored by organizations such as the Fraunhofer Institute and Renesas Electronics. At CVPR ‘23 we had the Princeton Computational Image lab create 2D “images” using beamforming (more on this later) from passive acoustic listening and fused this with RGB camera data.
While the Princeton paper was highly influential to this work, our client was interested in passing certain scenarios only without overly relying on (or expending energy on) a highly complex multi-dimensional sensor modality. In this post we explore several motivations for adding a simpler version of passive acoustic sensing to the autonomous vehicle sensor stack.
Sneak Peek of our solution: Flashing red/cyan vehicle is emitting sound
Why consider acoustic sensing?
Obstructed-view scenarios are increasingly emphasized in safety standards such as Euro NACP. Detecting hazards before they become visible is critical for improving safety metrics.
With the rise of autonomous systems in defense and security applications, additional sensing modalities may provide a differentiator when competing for contracts.
Sound does not require line-of-sight (LoS). Important events such as children playing in the street, emergency vehicle sirens, or approaching traffic can be detected even when visually occluded.
Sound is a natural communication modality for humans, and could provide a mechanism for richer interaction between the environment and the ego vehicle.
Acoustic signals can intrinsically provide directional information (heading), which can improve situational awareness metrics such as MAPH (Mean Average Precision with Heading).
Beamforming+RGB outperforms RGB alone in challenging occluded scenarios
Key disadvantages
Acoustic sensing also introduces several challenges:
Passive acoustic systems typically provide Angle-of-Arrival (AoA) information but not reliable distance estimates.
Performance can degrade due to vehicle noise, wind noise, and environmental interference.
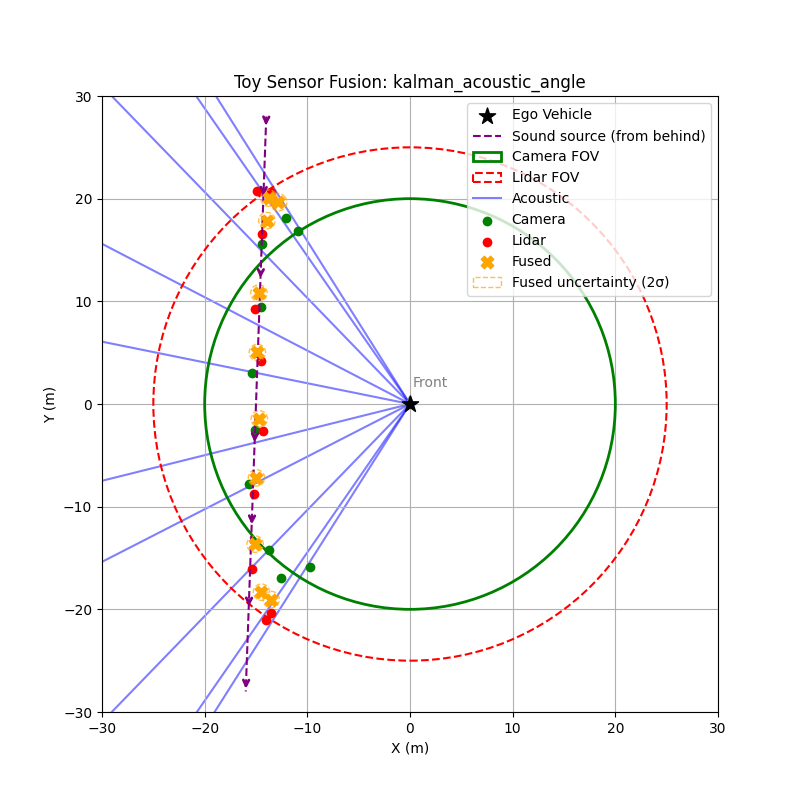
Toy Example: Acoustic Direction Improves Early Detection
To illustrate the value of acoustic sensing, consider a simple scenario:
An emergency vehicle approaches from the bottom-right relative to the ego vehicle.
Acoustic sensing estimates the direction of arrival using TDOA between microphones, but cannot determine distance.
Camera and lidar only detect the vehicle once it enters their field of view.
In the simulation, the vehicle moves toward the ego vehicle. The acoustic system continuously estimates a sextant, or directional sector, while the camera and lidar begin detecting the vehicle only after it enters their sensing range.
This allows the fusion system to gain early directional awareness, giving planning systems a chance to anticipate the approaching vehicle before visual confirmation. Even though the acoustic angle estimate is noisy, it provides information beyond the field of view of both camera and lidar. After fusing with lidar and camera data, the system produces more accurate position estimates.
Context
The work described here was originally developed at Reality AI, which was later acquired by Renesas Electronics to explore the commercial feasibility of passive acoustic sensing in automotive systems. My role focused on scaling the solution and validating it across different environments.
We conducted experiments using simulated emergency sirens in multiple environments, including:
controlled warehouse setups
busy urban streets
open environments with realistic traffic noise
We also collaborated with external partners to collect additional datasets and explore multi-sensor fusion approaches.
In this article, I will explore PAMVON (Passive Acoustic Monitoring for Vehicles and Objects)—a system that uses microphone arrays, signal processing, and machine learning to detect and localize important acoustic events in the driving environment.
The work described here was originally developed at Reality AI, which was later acquired by Renesas Electronics to explore the commercial feasibility of passive acoustic sensing in automotive systems. My role focused on scaling the solution and validating it across different environments.
We conducted experiments using simulated emergency sirens in multiple environments, including:
controlled warehouse setups
busy urban streets
open environments with realistic traffic noise
We also collaborated with external partners to collect additional datasets and explore multi-sensor fusion approaches.
Passive Acoustic Monitoring (PAM)
Passive Acoustic Monitoring (PAM) detects environmental sounds without emitting signals. Instead, the system passively listens for events in the surrounding environment such as emergency vehicle sirens, horns, tire skids, engine noise, drones or machinery, and even children playing in the street.
The key advantage of this approach is that sound does not require line-of-sight. Important cues can be detected even when they are visually occluded, in low-light conditions, or in adverse weather. This makes acoustic sensing particularly attractive for early warning scenarios, such as an approaching ambulance that has not yet entered the field of view of the vehicle’s cameras or lidar.
Recent developments in multimodal large language models also change how one might think about acoustic perception. Rather than requiring a rigid classifier that assigns each sound to a predefined category, modern multimodal systems can reason over audio signals more flexibly and incorporate them into a broader contextual understanding of the scene. In practice this means the acoustic signal can act less as a strict classification task and more as an additional stream of environmental information that the perception system can interpret alongside vision and other sensor modalities.
Microphone Arrays and Beamforming
Sound (like light) travels in a straight line and therefore we need at least 4 microphones to provide an accurate estimate of the angle of arrival of the sound wave. A single microphone provides limited spatial information. To estimate where a sound originates, passive acoustic monitoring systems typically use small arrays of microphones. By observing the time differences between when a signal reaches each microphone, the system can estimate the direction of arrival of the sound source. Arrays also make it possible to improve signal quality by combining signals from multiple sensors.
In practice this enables several useful capabilities. The system can estimate the direction of arrival of a sound, approximate the location of the source under certain assumptions, and improve the signal-to-noise ratio by combining measurements across the array.
Beamforming is the signal processing technique that makes this possible. The idea is simple: signals arriving from a particular direction reach each microphone at slightly different times. By applying the appropriate delays and summing the signals together, the array reinforces sounds from the desired direction while suppressing sounds from other directions.
In practice the system estimates the relative delay between microphones using cross-correlation. When a sound arrives at the array, it reaches each microphone at slightly different times. By computing the cross-correlation between pairs of microphone signals, the system can estimate the time difference of arrival between them.
These time differences constrain the direction from which the sound could have originated. With multiple microphone pairs, the system can estimate a consistent direction of arrival for the source.
Once the delays are known, the array can also combine the microphone signals in a way that reinforces sounds coming from that direction while suppressing others. In effect, the array behaves like a steerable listening sensor that can focus on different parts of the acoustic scene.
Angle of Arrival (AoA) Estimation via Cross-Correlation
In a microphone array, a sound source reaches each microphone at slightly different times. By comparing these signals, the system can estimate the relative delay between them. A common way to do this is through cross-correlation, which measures how similar two signals are as one is shifted in time relative to the other.
For two microphone signals $x_1(t)$ and $x_2(t)$, the cross-correlation can be written as
In real environments, reflections and background noise can make the correlation peak less reliable. A commonly used approach to improve robustness is generalized cross-correlation with phase transform (GCC-PHAT). This method emphasizes phase information in the frequency domain and reduces the influence of signal magnitude differences:
Here $X_1(f)$ and $X_2(f)$ are the Fourier transforms of the microphone signals. The peak of $R_{12}(\tau)$ provides a stable estimate of the arrival delay, which can then be used to infer the direction of the sound source.
Signal Processing Pipeline
Passive acoustic monitoring typically follows a structured processing pipeline:
Preprocessing: The raw microphone signals are filtered to remove irrelevant frequency bands, and gain normalization ensures consistent amplitude levels across microphones.
Time-frequency analysis: Signals are converted into spectrograms using the Short-Time Fourier Transform (STFT), revealing how frequency content evolves over time.
Beamforming: Directional enhancement techniques, such as delay-and-sum or cross-correlation-based beamforming, focus on sounds from specific directions while suppressing noise and interference.
Event detection: Open-source neural networks, including VGGish, convolutional-recurrent networks (CRNNs), and transformers, analyze the spectrograms to detect and classify events such as sirens, horns, or tire skids.
Localization: Time Difference of Arrival (TDOA) estimates, often computed using GCC-PHAT cross-correlation, are combined across microphone pairs to infer the direction of incoming sounds and, in some cases, approximate source locations.
This pipeline allows the system to transform raw audio into actionable information for autonomous vehicle perception, providing early warning of hazards even when they are outside the line of sight of cameras or lidar.
Acoustic Sensor Data Representation
In a generalized form, data from a passive acoustic monitoring array can be represented as a tuple capturing the relevant information for fusion:
$\theta$: Estimated angle of arrival (AoA) of the sound, typically computed using TDOA and cross-correlation (GCC-PHAT).
$\sigma_\theta$: Uncertainty of the angle estimate, reflecting noise, reverberation, or low SNR.
$c$: Sound class probability vector produced by the ML model. The classes correspond to ambulance, police, and other unknown loud sounds. For example, $c = [0.7, 0.2, 0.1]$
$f$: Frequency-domain features, such as Mel spectrogram or STFT frame, optionally used for downstream ML fusion.
$t$: Timestamp of the measurement, to allow temporal alignment with other sensors.
$\mathbf{p}_{\text{ego}}$: Pose of the ego vehicle when the measurement was captured, typically $(x, y, \psi)$ in 2D or 3D coordinates.
This representation allows the acoustic signal to integrate easily into perception and fusion pipelines:
$\theta$ provides a directional prior for early detection.
$c$ informs semantic understanding of the source.
$\sigma_\theta$ can be used in probabilistic fusion (e.g., weighted averaging, Kalman updates).
$f$ allows future retraining or fine-tuning of ML models.
$t$ and $\mathbf{p}_{\text{ego}}$ allow projection into bird’s-eye view (BEV) maps or occupancy grids alongside camera and lidar data.
For an array of $N$ microphones, the raw signals can also be stored as:
These raw signals are processed into the generalized form above, providing a compact yet rich representation for sensor fusion.
Simple ID-Based Matching
Before exploring a more technical late fusion approach, we first evaluated a simpler strategy based on ID matching. In this setup, acoustic detections were associated directly with annotated object identities in the dataset.
The acoustic classifier produced class probabilities for events such as ambulance sirens, police sirens, or other loud sounds. When the classifier detected a high probability ambulance siren, we matched that event to the corresponding object detection annotation in the scene. In practice this meant associating the acoustic event with the object ID labeled as an emergency vehicle in the perception dataset.
One challenge is that the acoustic detector often produces a directional estimate much earlier than the moment when the vehicle becomes visible and is annotated by the vision system. The acoustic pipeline provides an angle of arrival $\theta$, but not a direct range estimate. To place this information in the BEV representation, we projected the acoustic bearing into the map by creating an artificial point along the direction of arrival at a fixed distance $d$ from the ego vehicle. The distance was chosen to be larger than the field of view of the camera and lidar sensors so that the acoustic signal could represent a potential source outside the current perception range.
where $(x_{ego}, y_{ego})$ is the position of the ego vehicle in BEV coordinates. As the vehicle approaches and eventually enters the sensor field of view, the projected acoustic point becomes spatially consistent with the detected object.
This approach relies on the object detection pipeline already identifying vehicles and assigning consistent IDs across frames. The acoustic system then acts as an additional signal that confirms the presence of a specific type of vehicle.
Although simple, this method is surprisingly effective. The acoustic cue provides early detection of emergency vehicles, while the vision system provides precise localization and tracking. By linking the acoustic classification to existing object IDs, the system can quickly identify which tracked object is likely producing the sound.
This ID-based matching served as a useful baseline before implementing a more general late fusion approach using probabilistic tracking and bearing measurements.
Late Fusion with an Existing BEV Pipeline
While the ID-based matching approach provided a strong baseline, it relies on the object already being detected and assigned an identity by the perception pipeline. In many cases the acoustic signal appears earlier, before the vehicle enters the field of view of the cameras or lidar. To make better use of this early directional information, we extended the system using a more formal late fusion approach.
In this setup, acoustic sensing was integrated on top of an existing lidar and camera perception stack. The vision and lidar pipeline already produced tracked objects in bird’s-eye view (BEV), including estimates of position, velocity, and uncertainty. The acoustic sensor then contributed an additional bearing measurement, which could be incorporated into the tracking framework to refine object estimates and improve situational awareness.
After lidar and camera fusion, each tracked object is represented by a state vector
where $(x,y)$ represents the position of the object in BEV coordinates and $(v_x, v_y)$ represents the velocity components. The tracker also maintains a covariance matrix
$$\mathbf{P}$$
which represents the uncertainty of the state estimate.
The acoustic system produces a bearing measurement corresponding to the direction of arrival of the sound:
$$z_{ac} = \theta$$
where $\theta$ is the estimated angle of arrival relative to the ego vehicle.
If the ego vehicle is located at position $(x_e, y_e)$, the predicted bearing of a tracked object can be written as
$$h(\mathbf{x}) =\arctan2(y - y_e, \; x - x_e)$$
This function maps the tracked object position into the expected acoustic measurement.
The difference between the observed bearing and the predicted bearing is the innovation:
$$\mathbf{y} = z_{ac} - h(\mathbf{x})$$
Because the measurement model is nonlinear, we linearize it using the Jacobian
$$\mathbf{P}_{new} = (I - \mathbf{K}\mathbf{H})\mathbf{P}$$
Since the acoustic sensor only provides directional information, this update primarily reduces uncertainty perpendicular to the acoustic ray while leaving uncertainty along the ray largely unchanged. In practice, this allows acoustic measurements to improve the tracking of objects detected by lidar and camera without requiring modifications to the existing perception pipeline.
Final Output
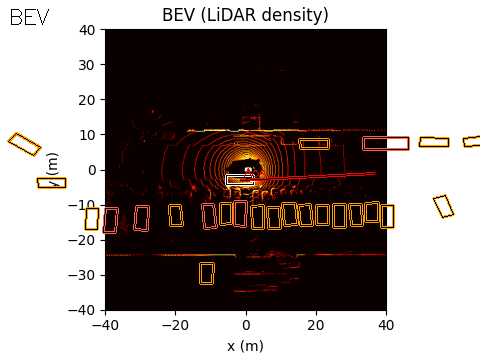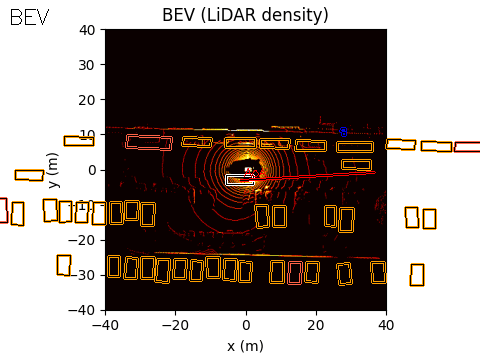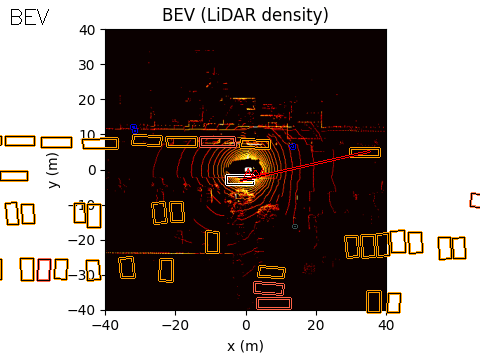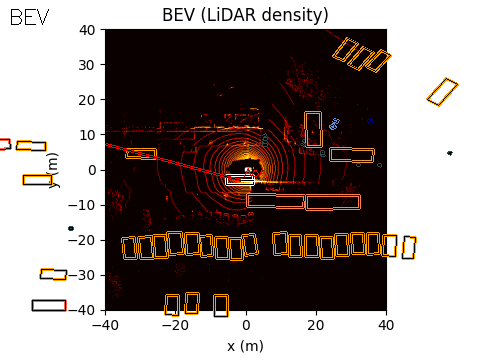
The final output of the system is represented in Bird’s-Eye View (BEV) space. The acoustic information can be projected into this space using either of the two methods discussed earlier.
In the example scene below, the ego vehicle drives past a stationary car that is simulated to emit an emergency vehicle siren. The figure illustrates how the acoustic signal integrates with the rest of the perception stack.
On the left, we show the acoustic output tagged with an object ID from the real-time object detection system provided by the customer (likely based on a model such as YOLO).
In the centre, we show the BEV representation, where the estimated angle of arrival (AoA) from the microphone array is plotted as a ray originating from the ego vehicle. Because the clip is only six seconds long, the visualization shows a ray pointing in the direction of the detected emergency vehicle sound from the start of the sequence. In this case, the microphones detect the siren before the object enters the field of view of either the camera or the lidar.
Once the vision-based detector identifies the vehicle, the AoA estimate can be associated with that object, with small corrections applied if necessary to account for sensor alignment or localisation error.
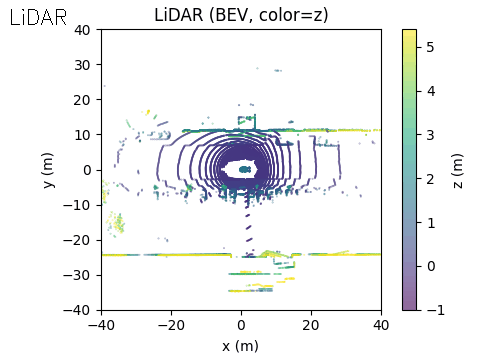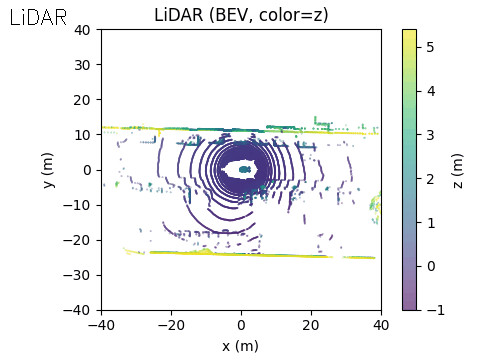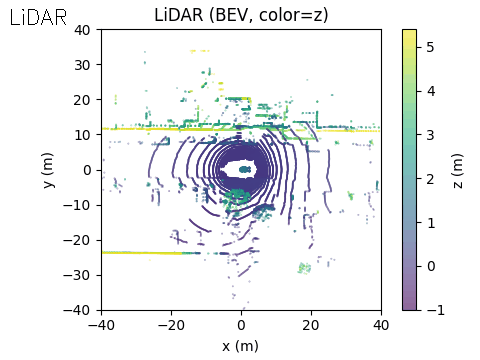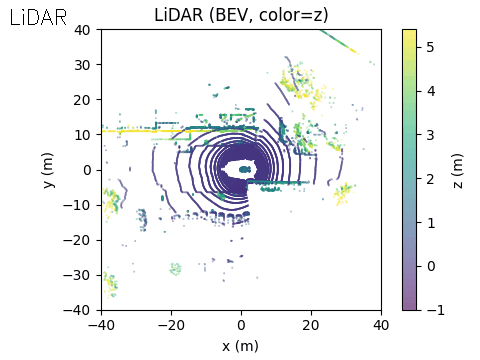
On the right, we show the lidar point cloud for the same scene. In this example, the acoustic output is not annotated in the lidar view, although such a visualization is also possible.
Camera: Flashing red/cyan vehicle is emitting sound
BEV: Acoustic AoA Plotted
LiDAR
Implementation Considerations
The passive acoustic monitoring pipeline can be implemented efficiently on embedded automotive hardware. In our implementation, the audio processing pipeline, machine learning inference, and angle of arrival estimation were designed to run on a single MCU core. This includes signal preprocessing, spectrogram generation, neural network inference, and cross-correlation based localization.
The system was implemented on Renesas automotive controllers, specifically the RH850 microcontroller family. Audio input processing, AI target detection, and angle of arrival estimation ran on a single RH850 core alongside the A2B audio stack. In this configuration the full acoustic pipeline occupied roughly 300 KB of code space, even while running in a debug configuration and without aggressive optimization.
This relatively small footprint makes it feasible to deploy acoustic sensing alongside other perception tasks without requiring specialized hardware acceleration. On RH850 devices, significant CPU, flash, and RAM resources remain available for additional vehicle functions.
Microphone array configurations can also be adapted depending on coverage requirements. A four-microphone array provides approximately 180 degrees of coverage, while an eight-microphone configuration enables full 360 degree sensing around the vehicle.
In practice, the computational requirements depend on the complexity of the processing pipeline. Efficient PAM processing can run entirely on automotive-grade microcontrollers such as the RH850. Larger microphone arrays or more complex neural networks may benefit from more powerful automotive SoCs such as the Renesas R-Car platform. Regardless of the hardware platform, maintaining real-time processing is critical so that acoustic events can be incorporated into the perception pipeline with minimal latency.
Passive acoustic monitoring has shown significant potential but has not yet become standard in autonomous vehicle perception stacks. There are several challenges that limit its adoption:
Ambient noise and signal variability – urban environments are full of sounds that can mask sirens, horns, and other important cues.
Environmental acoustic complexity – reflections, occlusions, and vibrations from the vehicle itself make accurate localization difficult.
Automotive qualification and safety standards – microphones and processing hardware must meet rigorous requirements such as ISO 26262 and AEC-Q100, and survive extreme temperatures and vibrations.
Limited generalization of machine learning models – systems that perform well in controlled tests can struggle on highways, in multi-siren urban settings, or with unusual sound events.
No regulatory requirement – without a mandate from safety standards or OEMs, there is little commercial incentive to integrate acoustic sensing into production vehicles.
Despite these obstacles, acoustic sensing can still provide value when used as a complementary modality. Integrating sound cues through late fusion on top of camera and lidar tracks allows early warnings of approaching emergency vehicles or other hazards, even before they enter the field of view. In this way, the acoustic signal reinforces and augments traditional sensors, enhancing situational awareness without requiring a full redesign of the perception stack. Performance improvements were observed in EuroNACP obstructed view testing scenarios, demonstrating the practical benefit of including an acoustic modality in complex urban environments.
]]>
https://franciscormendes.github.io/2026/03/07/acoustic-sensor-fusion/2026-03-07T00:00:00.000ZExploring PAMVON, a passive acoustic monitoring system for emergency vehicle detection, and the challenges preventing its production adoption.Beyond Photons: Passive Acoustic Sensing for Autonomous Vehicles2026-04-10T11:52:56.822ZFrancisco Romaldo Fernandes MendesIntroduction
Sometimes it does seem like my blog is just increasingly complex applications of the Fourier Transform. In the previous post we applied the Fourier Transform to graphs, drawing connections between frequency (which is the usual Fourier transform) and properties of the graph. There is yet another interesting, if abstract, application of the Fourier transform that is used in Quantum computers. Somewhat surprisingly, it is called the “Quantum Fourier Transform”. More specifically, we will study how the Fourier Transform appears as a unitary linear operator acting on quantum states.
At the end of the day this is all just linear algebra, requiring no knowledge of actual quantum physics. Because the Quantum Fourier Transform can be somewhat mathematically abstract and also because the Fourier Transform is so easily visualized as a decomposition into various sines and cosines, I thought of coming up with a similar visualization for the Quantum Fourier Transform case (spoiler: it involves clocks).
Motivation
Before discussing in detail what the QFT is mathematically, it is useful to recap what the Fourier transform is in general. The Fourier transform is a way of transforming information from one domain to another domain. Why? Because certain operations become simpler in the transformed domain. For example, in classical signal processing, convolution of a signal (the mathematical definition of filtering) in the time domain corresponds to simple multiplication in the frequency domain.
In the graph setting, we saw that potentially complex behaviors in the edge-node representation of the graph were far more mathematically tractable when looking at the “frequency” equivalent of the graph. Eigenvectors of the graph Laplacian isolate modes of variation: low-frequency components capture global structure, while high-frequency components capture local fluctuations.
Similarly, for the Quantum Fourier Transform, we move from a bit representation of a number to a cyclical or phase representation. In the computational basis, information is stored as binary digits, essentially a sequence of ON/OFF switches taking values in $\{0,1\}$.
In this form, the data is linear and rigid. Any underlying periodic structure is hidden inside the positional encoding. Phases, however, live on the circle and are inherently cyclical. If we want to detect periodicity or modular structure, it is more natural to encode information as rotations rather than switches.
The QFT therefore plays the same conceptual role as the classical Fourier transform: it changes coordinates to a representation in which the problem’s hidden structure becomes easier to manipulate.
I might do a post later on why this is true on so many different problems. But it is not true for some problems such as when you need convolution to learn a local filter.
Useful Intuition
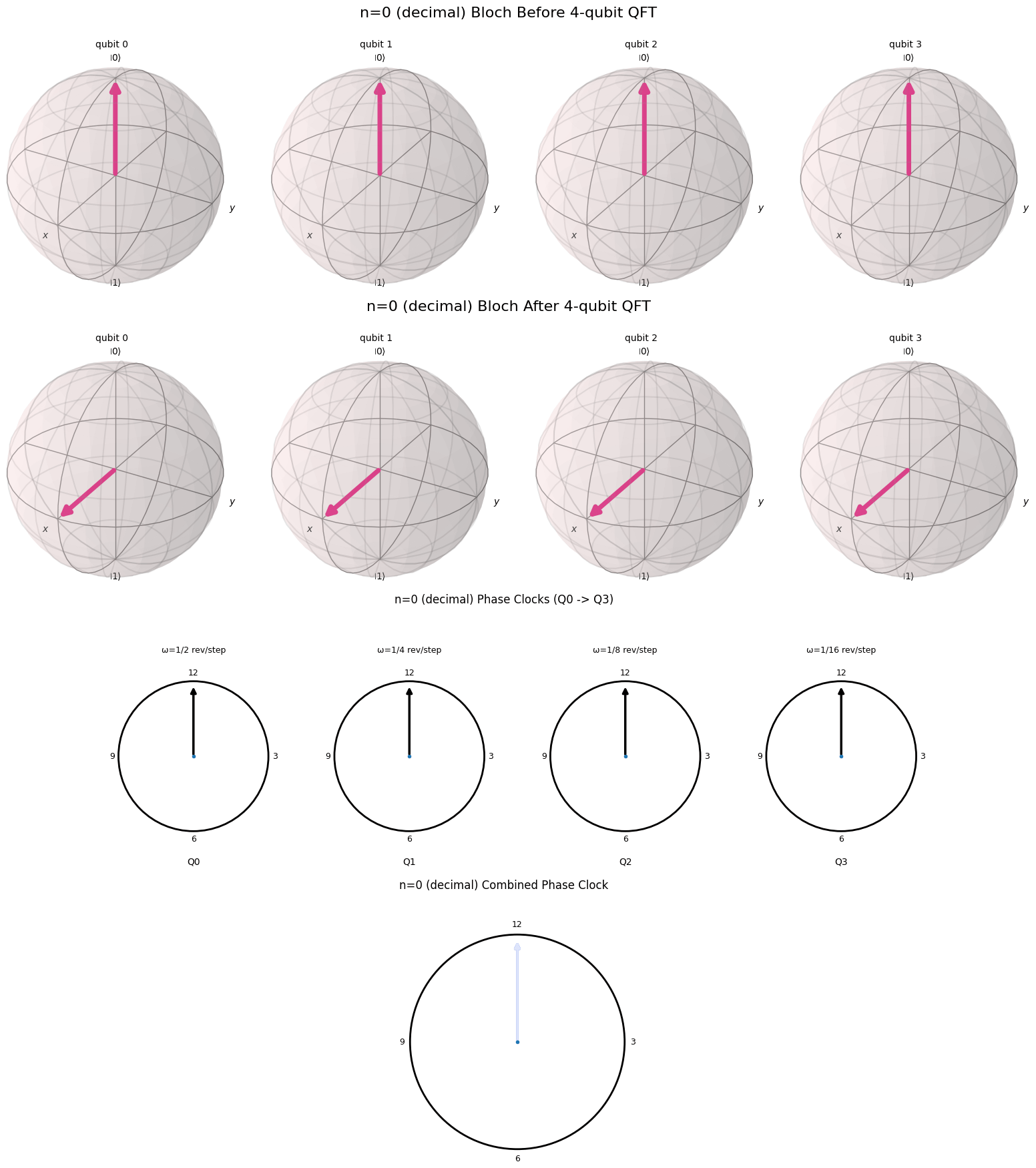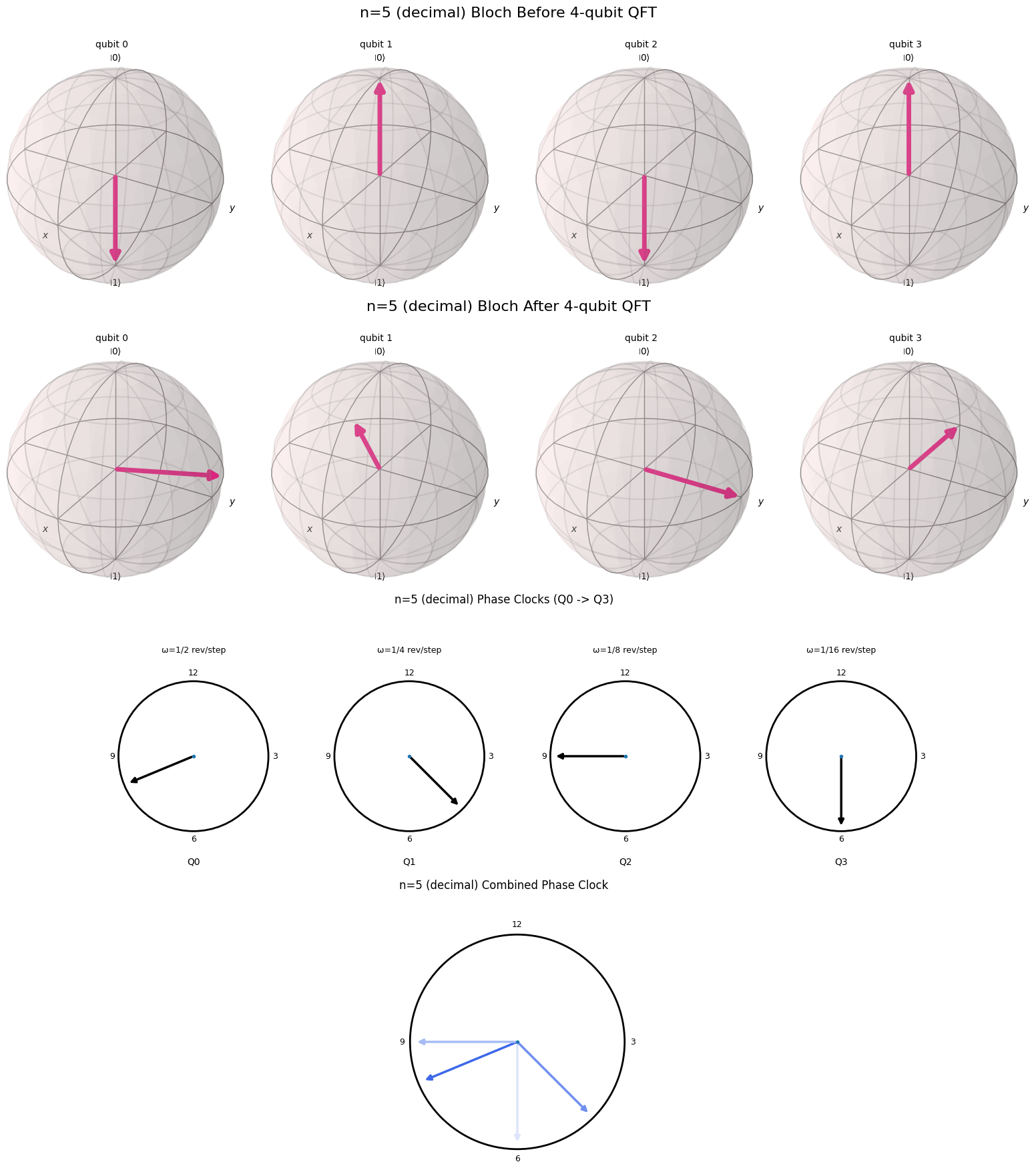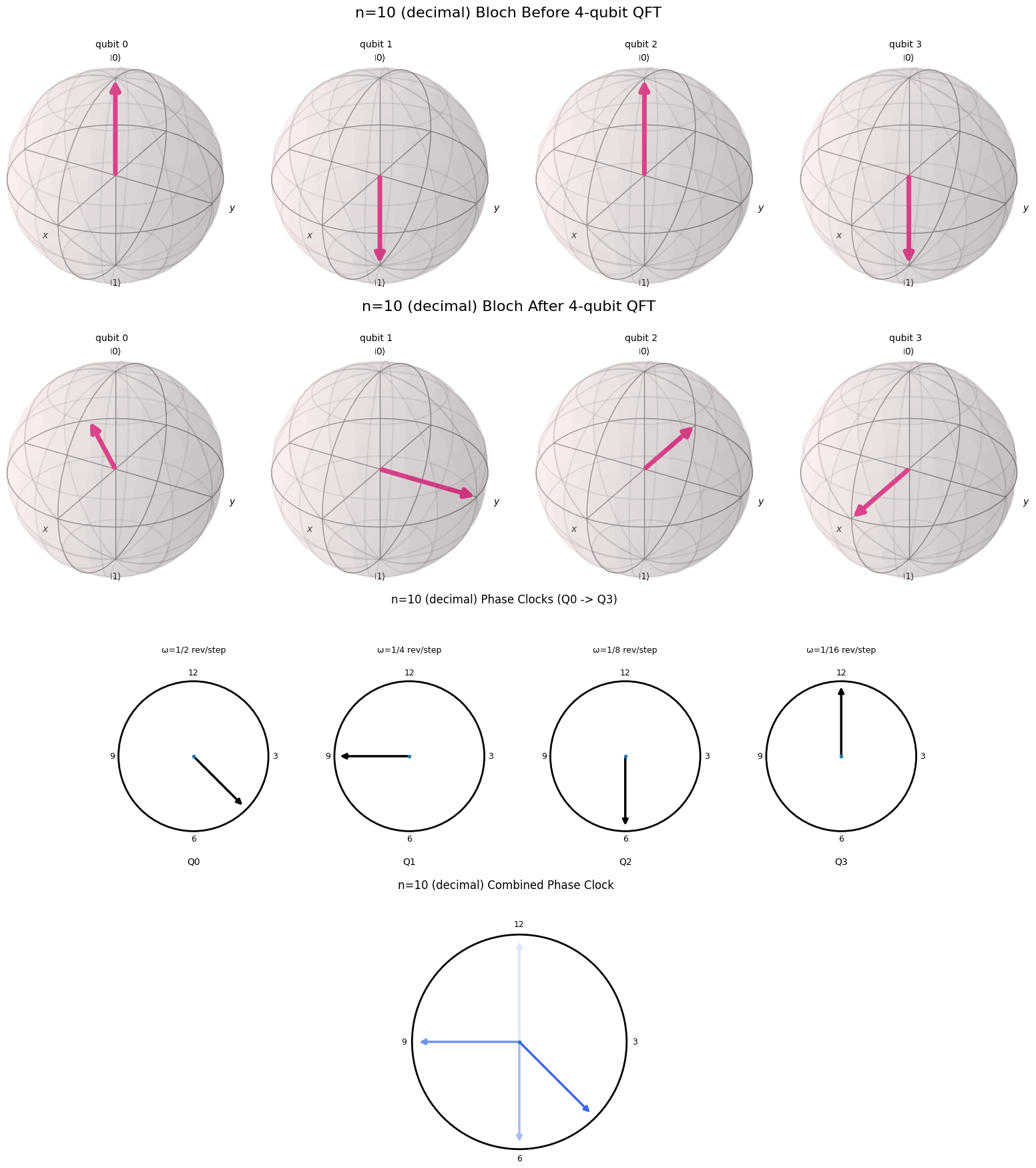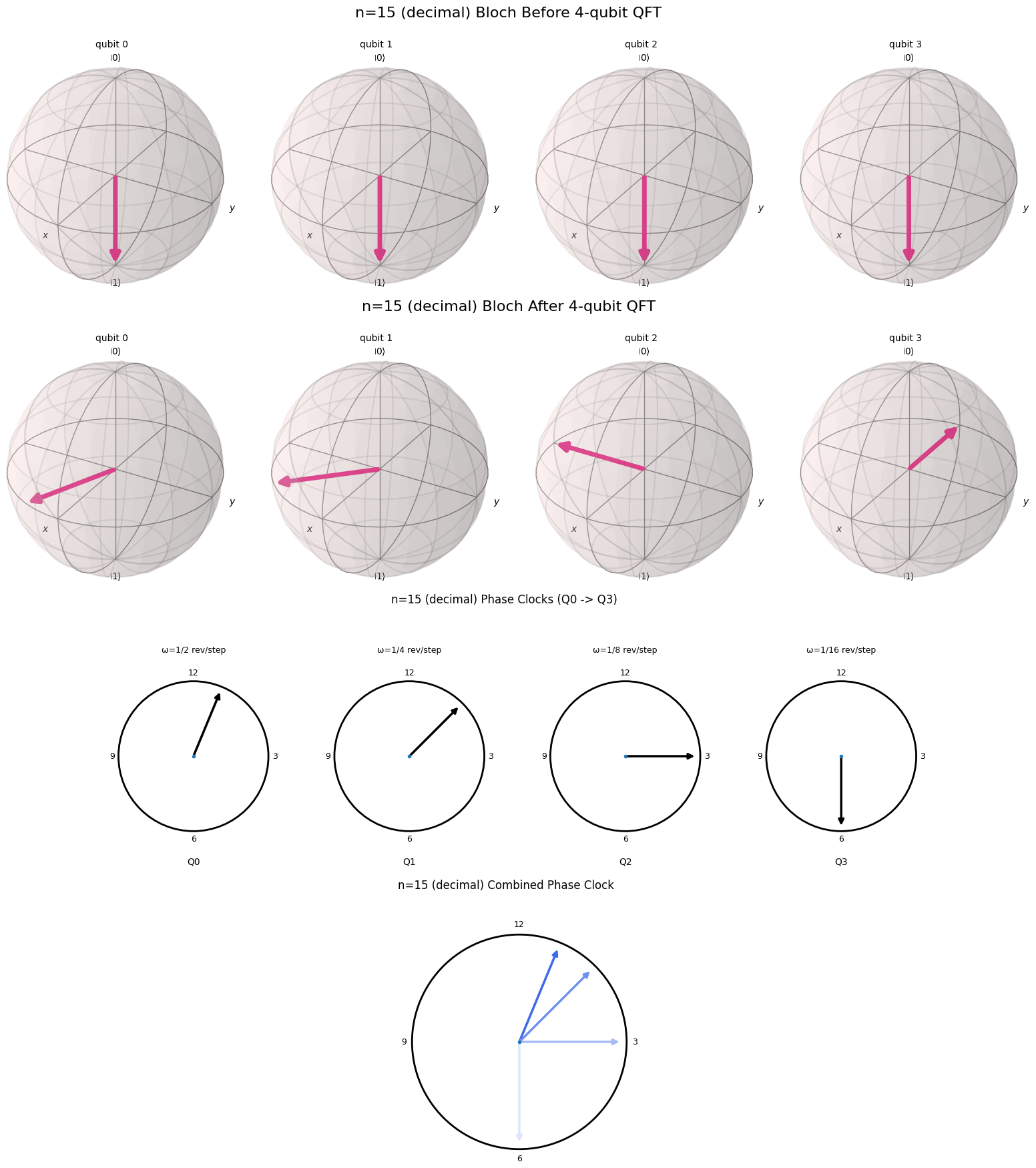
One of the reasons the Fourier transform in its simplest form is so interesting is that it is so visual. In this blog post I will try to provide a nice visual explanation for the QFT. Essentially we want to draw a connection between the binary representation of a number and the cyclical nature of the QFT. Fortunately, there is a nice visual representation for a binary representation of a number on a computer, called a qubit. This representation of a number is called a qubit.
A Useful Visualization
]]>
https://franciscormendes.github.io/2026/02/28/quantum-fourier-transform/2026-02-28T00:00:00.000ZVisual guide to the Quantum Fourier Transform: from binary numbers and roots of unity to the QFT circuit, with comparisons to classical DFT and implications for Shor's algorithm.From Bits to Clocks: A Visual Intuition for the Quantum Fourier Transform2026-04-10T14:24:00.558ZFrancisco Romaldo Fernandes MendesIntroduction
I was recently invited back to the MA department at UChicago for a career conference. Sitting there, listening and speaking, I found myself asking a rather uncomfortable question:
How much of what we value in education is pure signaling? Is this still true in the age of AI?
It is perhaps an opportune moment to recap the signaling model of education. In labour markets with asymmetric information, employers cannot directly observe ability. In Michael Spence’s signaling model, education does not necessarily increase productivity; instead, it separates high-ability individuals from others because it is less costly for them to acquire. In this paradigm, education serves as a “signal” of ability.
I think AI has changed this status quo because the cost of acquiring education has reduced to the point that there is no cost differential between high-ability and low-ability individuals for a large number of courses. To be more specific, the cost of sending a signal of education is reduced to the point of being indistinguishable between both groups. The cost of actually educating oneself is likely still lower for high-ability individuals, it’s just that sending this signal is easier.
This essay is intended to answer some of the questions that I recieved at the conference, some of which are outlined below,
But what does “actually” educating oneself really mean?
What does it look like? Which classes should I take?
What should be the emphasis of my self-study?
How do I position myself best for the job market?
Beyond The Signal: So What Should I Study?
In the old (read: pre-AI) world where education was largely signaling, I think taking classes that superficially but with high probability signaled education, such as cloud skills, basic Python programming, and machine learning applications, were good enough. But in the new world, the cost of acquiring these skills is zero. Thus high-ability individuals need to seek out higher difficulty tasks that are relatively lower cost for them to acquire in order to send a strong signal. Mathematical maturity, comfort with abstraction, and disciplined reasoning are not signals in themselves; they are capabilities that affect what you can build, debug, or invent.
Thus class choices should reflect these core values:
Mathematical courses that emphasize the core mathematics that make up machine learning, such as linear algebra and differential equations
Looking under the hood of machine learning, focusing on the mathematical fundamentals of machine learning
Social sciences courses that challenge your world view and force you to think about what the world should look like (more on this below)
Good Intellectual Health
More important than ever, and not specific to tech jobs but just life in general, is maintaining good intellectual health.
Reading books both in your field and outside of it is now more important than perhaps in the world before AI. Using AI increases one’s distance from one’s self. One’s ideas and one’s thoughts are now further than ever from one’s own experience. Reading books and writing reduces this distance. Since idea generation and critical thinking depend so heavily not only on the final output but also on the process by which one reaches it, exercising this muscle is now more important than ever.
Maintaining good intellectual health, however, is almost entirely self-policed. There are very few reliable ways to monitor how much AI shapes one’s own work. What usually starts as submitting homework in a rush can escalate to generating entire essays using AI, the slope is truly slippery. One cannot afford to replace the cognitive effort that builds depth, originality, and judgment. Only you can decide if the level of AI use hampers your intellectual health, and only you can feel its effects.
Emphasizing the Social Sciences
The sciences are exceptionally good at helping us understand what the world is. As a result, advice about improving technical skills tends to be prescriptive and measurable. The social sciences operate differently. They help us think about what the world should look like. They force us to articulate assumptions about behaviour, incentives, norms, and institutions. The process of forming a view about what the world ought to be is central to intellectual health. It requires reflection, judgment, and an awareness of values, not just optimisation. Admittedly, this is difficult advice to give at a career conference for students focused purely on technical roles. The impact of studying sociology, psychology, or economics is harder to measure in a tech performance review. It doesn’t map cleanly onto a skills matrix. But it is no less important for that reason. The social sciences implicitly construct world models. Whether in sociology, psychology, or economics, they offer structured ways of thinking about how systems of people behave. That kind of world-building is essential for understanding where highly parameterised models, such as those produced in machine learning, actually live. Models do not operate in a vacuum; they operate within social and economic systems.
This becomes even clearer in business contexts. Firms operate with explicit views of what the world should look like, in terms of acquisition, churn, retention, revenue. Machine learning systems are deployed inside those normative visions. I admit there is something slightly distasteful about motivating the social sciences purely in terms of churn or revenue. It feels almost sacrilegious. But in practice, those incentives shape the environments in which technical systems are built. And if that were not the case, the audience at a career conference might be asking very different questions, comrade.
TL;DR;
The “sticker” value of UChicago’s education has held steady relative to other similar institutions. It might even have appreciated slightly. However, the absolute “sticker” value of education as a signal of ability in top schools (and indeed everywhere else) has gone down. Thus the onus is now on students to take courses that more appropriately signal their ability, not just in purely technical terms (such as mathematics, physics, machine learning) but also in critical thinking terms (such as expertise in the social sciences). The days of superficial knowledge that use model.fit(X) are over.
The UChicago brand will likely hold its value for years to come but it is not going to be enough. Even though the bar to have superficial knowledge is lowered thus muddying the difference between high and low skill individuals, the bar to have truly fundamental understanding of the sciences including (and perhaps especially) the social sciences is has never been higher.
]]>
https://franciscormendes.github.io/2026/02/20/ssd-career-conference/2026-02-20T00:00:00.000ZSpence's signaling model updated for AI: when the cost of educational signaling collapses to near-zero, what genuine intellectual skill looks like and how to build it.Signaling, Skills, and Intellectual Health in the Age of AI: Thoughts from UChicago Career Conference 20262026-04-10T14:24:00.564ZFrancisco Romaldo Fernandes MendesIntroduction
I did not spend my twenties reading Murakami, when it was all the vogue. Now, having read three works of his, I feel an upswell of opinions on his work and writing. We will explore some of the themes of Murakami as well as the cultural symbol that he has become. He was the kind of writer you are almost supposed to like as a young man.
Murakami seemed like the sort of writer you are supposed to like, especially in your twenties. Sadly, my twenties flew by rather quickly without so much as a glance at a Murakami novel. And there were several — part of Murakami’s appeal is how prolific he is across a variety of genres. Now in my, arguably still early, thirties I have read three novels of his: Kafka on the Shore, First Person Singular, and The Wind-Up Bird Chronicle. While my views on Murakami remain lukewarm at best, his writing certainly inspires deeper engagement with broader themes in society.
Writing
The English literary tradition has always been deeply rooted in the beauty of language; it is almost as if the words carrying the story must match the beauty of the story itself. The result can be complex, layered prose that oftentimes outlasts the literary work itself. Very often from the opening lines themselves, the classics sought to set the stage with beautiful prose.
“Call me Ishmael…”, “It was the best of times, it was the worst of times…”
Compare this with Murakami, whose writing proceeds forth incessantly in its banality. The words easily slide off the page as if narrated by a friend over the telephone. The words do not linger; they hurry off the page carrying their message with great efficacy. He does not, however, use this efficiency to drive more of the plot forward, choosing instead to match the banality of his prose with descriptions of the banalities of the human condition — eating, sleeping, and listening to music. It seems as if Murakami rejects the aestheticism of both the prose and the story. One cannot imagine Dickens devoting a paragraph to what the main character ate for breakfast.
One should not leave with the impression that the resulting writing is uninspired or insipid. On the contrary, the effect of his writing is a highly atmospheric narrative style that attenuates his trademark surrealistic elements. The banalities serve to obscure or highlight the passage of time, a critical element of his surrealistic themes. The reader is drawn into a different world, and very often drawn into a different supernatural world within that world.
A long-standing critique of English literature prior to Murakami was that it was almost inaccessible to people learning English for the first time. In my eyes this was largely a consequence of English speakers dominating English writing, whereas Murakami does not speak English as his first language. Nothing exemplifies this more than the fact that Murakami came upon his extraordinarily simple writing style by simply translating his English prose to Japanese and then back, thus losing all but its most essential elements. Literary essentialism, some (this author) would call it.
Nothing is happening here. The shrine stands. The snow falls. And yet — this is precisely the kind of scene Murakami would spend three pages on, and you would read every word of it. The atmosphere is the point; the banality is the vehicle. This is the closest image I can find to what it actually feels like to read him.
Eastern Storytelling
There is a tension between Eastern and Western storytelling, and this tension is apparent even in the differences in children’s stories. In Grimm’s fairy tales, for example, we have a clearly defined protagonist who must weather the odds, defeat the antagonist, and eventually prevails. In Eastern storytelling the beauty of the story is much more important than what the story means. Consider The Crane Wife, a well-known Japanese children’s story. A crane transforms into a beautiful woman; this beautiful woman proposes to a poor fisherman. The fisherman agrees, but the woman imposes one condition: he can never look at her when she is weeping. One day the fisherman looks at her while she weeps; he sees that she is a white crane. He leaves her. The story ends, rather abruptly. This ending is rather distressing, especially to Western audiences. Why does the story end? The ending is so sad — how can it end yet? What does this all mean? Beauty, I suppose, is the key to this difference. This is a beautiful story and the sadness is beautiful.
The moon reflects on the water. The islands sit in the dark. No story. No explanation. No moral. And it does not matter — the image is enough. This is what Eastern aesthetic beauty looks like when it works. Murakami is reaching for something like this. I am not always sure he grasps it.
I have the same visceral reaction to Murakami’s stories. I find myself asking at the end of every book:
But what does this all mean?
While I recognize that this cultural difference is at the heart of why people react negatively to Murakami’s writing, I find it hard to reconcile with the fact that Murakami’s writing forces you to do one of two things.
The first is to take the story literally. This involves taking every supernatural act, every bizarre event as literal and believing it. This is not hard — we do this to some degree with all works of fiction, from Tolkien to Kafka. We are (I am) willing to suspend disbelief. However, the stories take themselves seriously. In The Metamorphosis, while we are never offered an explanation for why Samsa is a monstrous insect, the reactions to him and his reactions to himself treat his metamorphosis as real. The story takes itself seriously and reconciles the apparent inexplicability of the metamorphosis as given. This is not the effect that Murakami’s writing has on me. His writing weakly evokes bizarre situations such as the insect; however, there are a great many such situations. The immoderation in the supernatural and the bizarre requires a much higher degree of suspension of disbelief, which makes it much harder for the reactions of other characters to be believable. It reminds me of the famous Christopher Nolan quote:
“It does not matter how believable the story is to you; the story must be believable to itself and its characters.”
It is this inviolable rule that is broken multiple times.
The second is to take the story as some kind of metaphor. Again, Kafka’s writing has this effect as well — we can think of the insect-like transformation of Gregor Samsa as a kind of moral corruption, stagnation, or emasculation. However, because Murakami uses characters, bizarre events, and other supernatural motifs so liberally, it is difficult for the metaphor to retain any coherent narrative structure, let alone a consistent representation of something else.
In both cases, it seems as if Murakami is willing to sacrifice coherence and linguistic beauty for some kind of narrative aesthetic. To me this sacrifice was not worth it, since there are far too many characters and motifs that seem to exist solely to move the plot along. Far too many characters are sacrificed on this imagined altar of aesthetic beauty. My objection does not arise out of a sense of wellbeing for these characters, but rather that they seem rather superficial — which leads naturally to my next criticism.
Superficiality
The main characters in Murakami’s books can be disappointingly without agency. They can seem as if they are carried away by the wave of the narrative. This matches Murakami’s style in his own words: he creates the characters first and then places them in a story. Almost like a simulation — this makes the storytelling easy.
Again, this could be the difference between Eastern and Western protagonists. I do not agree with this, however. I think Murakami’s characters are quite American in a modern way. The protagonist is like the main character in a pop culture film — hidden away, not a part of society. But then society needs him, or something happens to him, and he must act in the midst of it. In some strange way this superficiality matches the aesthetic of Murakami’s writing. In some ways, I consider Murakami to be a modern American author, as much as Paul Auster. To Murakami’s credit, I suspect this imitation might not be entirely unintentional. This imitation evokes the adoption of Western individualism by Japanese society — fairly thin, and without the corresponding import of Christian ethics. Murakami laments the lack of family connections in Japanese society.
Similarly, supporting characters exist only as reflections of the main character. In all the books that I read, I was not able to identify one single character that had anything remotely resembling a personality. Murakami writes a superficial main character and every other character exists to reflect that character back to himself. Bizarrely, Murakami’s novels feel two-dimensional — you are drawn into an atmospheric but ultimately flat world. Some things feel real, but the lack of dimension is apparent. It has to be said that this is appealing to some; others describe this as “dreamy”, “vague”, and “beautifully foggy”. It is likely that this flaw uniquely penetrates my intellectual armor more so than others.
I have many issues with the way women are written in Murakami’s novels. I will leave it at that.
Japanese Psyche
It is somewhat contradictory that Murakami is surprisingly modern, and almost comes across as an American writer in some sense. Yet the questions his books raise about Japanese identity — individualism imported wholesale from the West, the erosion of family and community — are distinctly Japanese concerns, and they are the more interesting for it.
Conclusion
I find myself, having now read three of his novels, in the rather uncomfortable position of a reluctant critic. Murakami is undeniably significant. He has done more for the global reach of Japanese literature than perhaps any other living author, and his ability to inhabit the borderlands between the real and the supernatural is a genuine literary achievement. His cultural impact is not nothing, as the young person in every bookshop clutching a copy of Norwegian Wood will attest.
But the books themselves leave me cold — not in a sterile sense. They are atmospheric, readable, and at times deeply evocative. I always emerge from them, however, without the feeling of having had a meaningful encounter with another human mind. The characters drift, the plots dissolve, and one is left with that same persistent question.
But what does this all mean?
I suspect that for his devoted readers, the answer is in the question itself. The asking is the point. The fog is the destination. I remain unconvinced, but I respect the fog.
Murakami’s world looks something like this — solid enough to walk through, obscured enough to never quite see the edges of. The fog does not owe you an explanation. I have made my peace with this, though not enough to enjoy it.
]]>
https://franciscormendes.github.io/2026/01/15/on-murakami/2026-01-15T00:00:00.000ZHaving now read three of his works — Kafka on the Shore, First Person Singular, and The Wind-Up Bird Chronicle — some lukewarm opinions on Murakami.On Murakami2026-04-10T12:14:28.067ZFrancisco Romaldo Fernandes MendesIntroduction
If you’ve ever come across the coastline paradox, you’ve probably seen the classic (and somewhat overused) image of the coastline of Britain. Recently, a friend asked me a question that felt like the 3D analogue of this paradox: What is the surface area of a city? More specifically, does a very hilly city have more surface area than a relatively flat one?
The answer, as it turns out, is more complicated than it first appears. My initial instinct was to treat this as the 3D version of the coastline paradox, and that idea sent me down a rabbit hole—one whose key insights form the basis of this blog post. Complete follow along notebook can be found here.
Here’s how the post is structured:
Visualizing the 2D coastline paradox using the Koch curve, a well-known fractal curve.
Extending this to the 3D case by visualizing the surface area paradox with a fractal terrain.
Applying these ideas to real-world GIS data to verify the paradox in practice.
Exploring the concept of dimension.
Point 4 turned out to be particularly enlightening. In researching this post, I realized that the way we commonly think about “dimension”—1D, 2D, 3D—is not mathematically rigorous. The coastline paradox and its 3D surface area counterpart only exist because our intuitive notion of dimension is incomplete. In fact, dimensions can be fractional, and by using the results from sections 1, 2, and 3, we can actually measure them and gain a deeper understanding of the geometry underlying these paradoxes.
2D Coastline Paradox
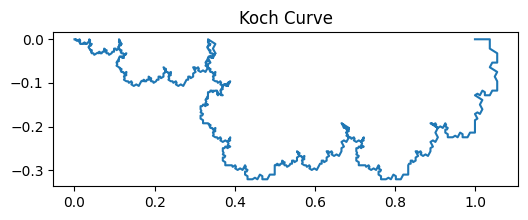
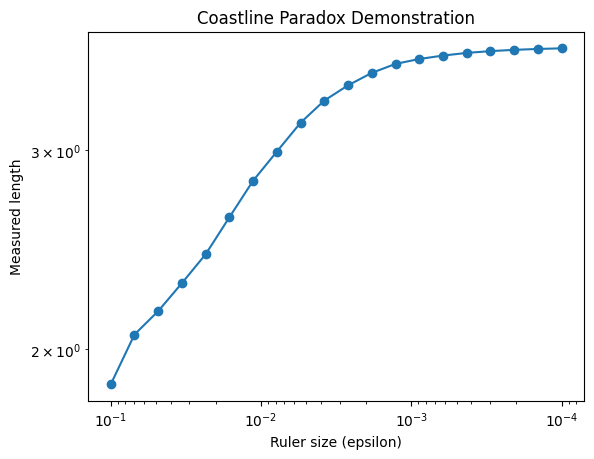
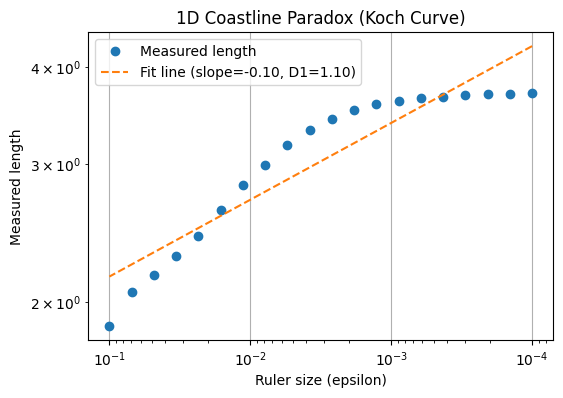
The figure above illustrates the coastline paradox using a Koch curve, a classic fractal curve. As the ruler size decreases, the measured length of the curve increases dramatically, highlighting that the “true” length of a jagged, self-similar shape is not well-defined. In the top plot, we visualise the Koch curve after six iterations, showing its intricate zig-zag pattern. The bottom plot demonstrates the paradox quantitatively: on a log–log scale, smaller ruler sizes (on the right) capture finer details, resulting in a rapidly increasing measured length. This simple experiment illustrates why fractal curves require a scale-invariant descriptor—the Minkowski or box-counting dimension—to characterise their complexity, rather than relying on a single length measurement.
The figures above illustrate the coastline paradox using a Koch curve, a classic fractal curve. As the ruler size decreases, the measured length of the curve increases dramatically, highlighting that the “true” length of a jagged, self-similar shape is not well-defined. In the top plot, we visualise the Koch curve after six iterations, showing its intricate zig-zag pattern. The bottom plot demonstrates the paradox quantitatively: on a log–log scale, smaller ruler sizes (on the right) capture finer details, resulting in a rapidly increasing measured length. This simple experiment illustrates why fractal curves require a scale-invariant descriptor—the Minkowski or box-counting dimension—to characterise their complexity, rather than relying on a single length measurement.
Mathematical Proof
Consider a jagged curve (e.g., a coastline) in 2D, and let $L(\varepsilon)$ denote the measured length using a ruler of size $\varepsilon$.
Divide the curve into segments of length $\varepsilon$. Let $N(\varepsilon)$ be the number of segments required to cover the curve:
If the curve is smooth: $D = 1$, then $L(\varepsilon) \sim \varepsilon^{0} = \text{constant}$.
If the curve is fractal: $D > 1$, then $L(\varepsilon) \to \infty$ as $\varepsilon \to 0$.
This demonstrates the paradox: the measured length depends on the ruler size, and only the fractal dimension $D$ provides a scale-invariant measure of the curve’s complexity.
On a log–log plot of $L(\varepsilon)$ vs $\varepsilon$, the slope is $1-D$.
This allows us to characterise the roughness of the curve quantitatively.
3D Coastline Paradox
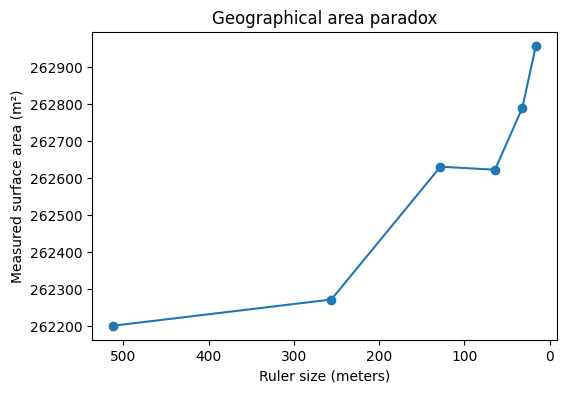
The figure below demonstrates the geographical area paradox, the 3D analogue of the coastline paradox. Here, we measure the surface area of a fractal terrain generated using the diamond-square algorithm. As the size of the measurement “ruler” (square grid) decreases, the measured surface area increases, revealing more of the fine-scale roughness of the terrain. Just as the length of a fractal curve diverges with smaller ruler sizes, the area of a fractal surface grows without bound. This shows that for rough surfaces, the conventional notion of area is ill-defined at very small scales. Instead, the fractal dimension of the surface provides a single, scale-invariant number that quantifies the complexity of the terrain.
Mathematical Formulation of the 3D Surface Paradox
Consider a 3D surface $z = f(x,y)$ defined over a 2D domain. Let $A(\varepsilon)$ denote the measured surface area using a square ruler of side $\varepsilon$.
Divide the plane into a grid of squares of side (\varepsilon). Let $N(\varepsilon)$ be the number of squares required to cover the surface (or, equivalently, the number of boxes intersecting the surface in 3D):
On a log–log plot of $A(\varepsilon)$ vs $\varepsilon$, the slope is $2$D.
This provides a scale-invariant measure of the surface’s roughness analogous to the 2D case but in two dimensions.
Telegraph Hill
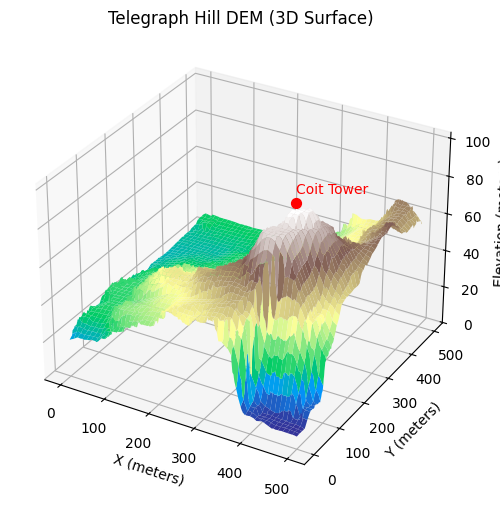
Up to this point, we have illustrated the coastline (or geographical area) paradox using a simulated fractal surface. While this is useful for building intuition, it is ultimately a controlled toy example. In this section, we replace the synthetic terrain with real elevation data from Telegraph Hill in San Francisco. Extracting and preparing this data turned out to be an ordeal in its own right—one that probably deserves a dedicated blog post. There is something uniquely satisfying about working with GIS data: every raster, projection, and coordinate transform is a walking demonstration of linear algebra in the wild. But I digress. With the elevation data in hand, we can now repeat the same multi-scale measurement exercise and observe the coastline paradox emerge not from a mathematical construction, but from an actual piece of geography.
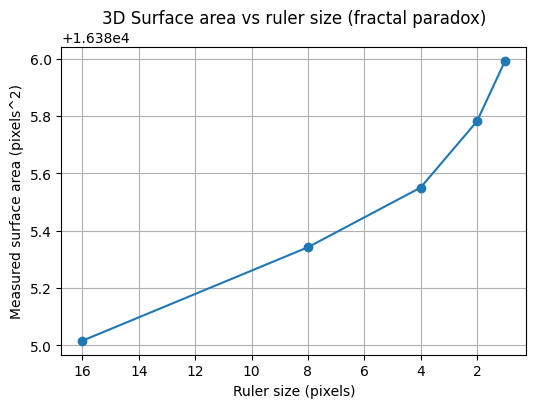
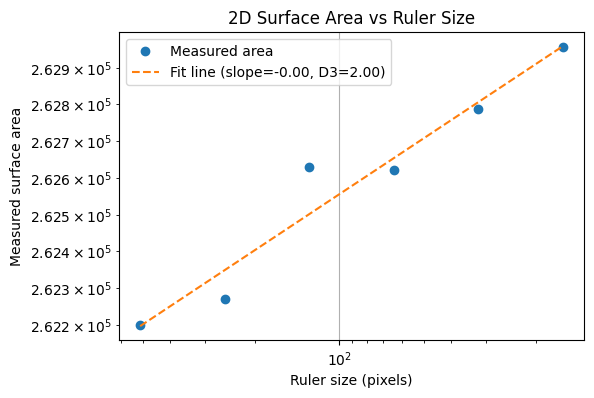
To illustrate the coastline paradox in a real geographical setting, we estimate the surface area of Telegraph Hill using progressively smaller “rulers.” In the code above, the terrain is measured with square rulers of 256, 128, 64, and 32 meters, and the total surface area is recomputed at each scale. As the ruler size decreases, the measured area systematically increases. This is not because the hill is physically changing, but because finer rulers capture more of the terrain’s small-scale roughness—minor ridges, gullies, and local slope variations that are invisible at coarser resolutions. The resulting curve demonstrates the geographical area paradox: for a rough, fractal-like surface, area is not a single well-defined number, but a scale-dependent quantity. What remains invariant across scales is not the measured area itself, but the rate at which it grows as the ruler size shrinks—an idea formalised by the surface’s fractal dimension.
Fractional Dimensions
So far, we have seen how measured length or surface area depends on the ruler size: smaller rulers reveal more detail, producing larger measured values. The key insight of fractal geometry is that this scale-dependence can be quantified by a fractional, scale-invariant dimension, also called the Minkowski–Bouligand dimension.
2D Case: Koch Curve
For a fractal curve, the measured length (L(\varepsilon)) scales with ruler size (\varepsilon) as:
$$L(\varepsilon) \sim \varepsilon^{1-D_1} = 1.1$$
where $D_1$ is the fractal dimension of the curve. By plotting $\log L(\varepsilon)$ versus $\log \varepsilon$, the slope of the line gives $1-D_1$, from which we can solve for $D_1$. For the Koch curve, this yields $D_1 \approx 1.1$ (theoretically this is $1.26$), reflecting that the curve is “rougher than a line” but does not fill a plane.
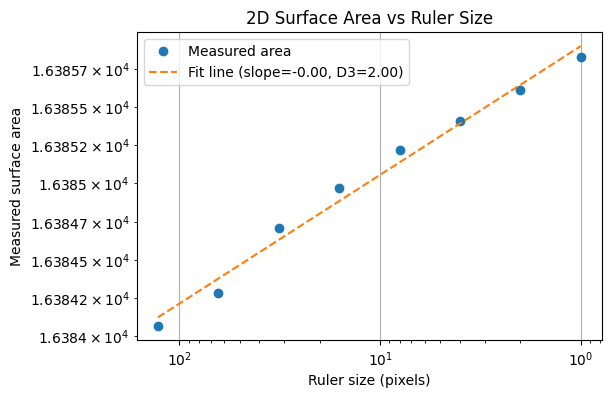
3D Case: Simulated Fractal Surface
For a fractal surface, the measured area $A(\varepsilon)$ scales with ruler size $\varepsilon$ as:
where (D_2) is the surface’s fractal dimension (with $2 < D_2 < 3$). A log–log plot of $A(\varepsilon)$ versus $\varepsilon$ gives a slope of $2-D_2$, allowing us to solve for $D_2$. In practice, simulated terrains often have $D_2 \approx 2.3{-}2.5$, meaning the surface is rougher than a plane but still does not fill 3D space.
Real-World Case: Telegraph Hill
Finally, we can apply the same method to elevation data from Telegraph Hill. Using square rulers of decreasing size, we measure the terrain’s surface area at each scale. A log–log plot of measured area versus ruler size produces a slope that corresponds to $2-D_{TH}$.
The resulting fractional dimension (D_{TH}) captures the true roughness of the hill, providing a quantitative, scale-invariant measure of the terrain’s complexity. Just like with the Koch curve or the simulated fractal surface, the hill exhibits a dimension that is between its topological dimension (2) and the embedding dimension (3), revealing the fractal nature of real-world landscapes.
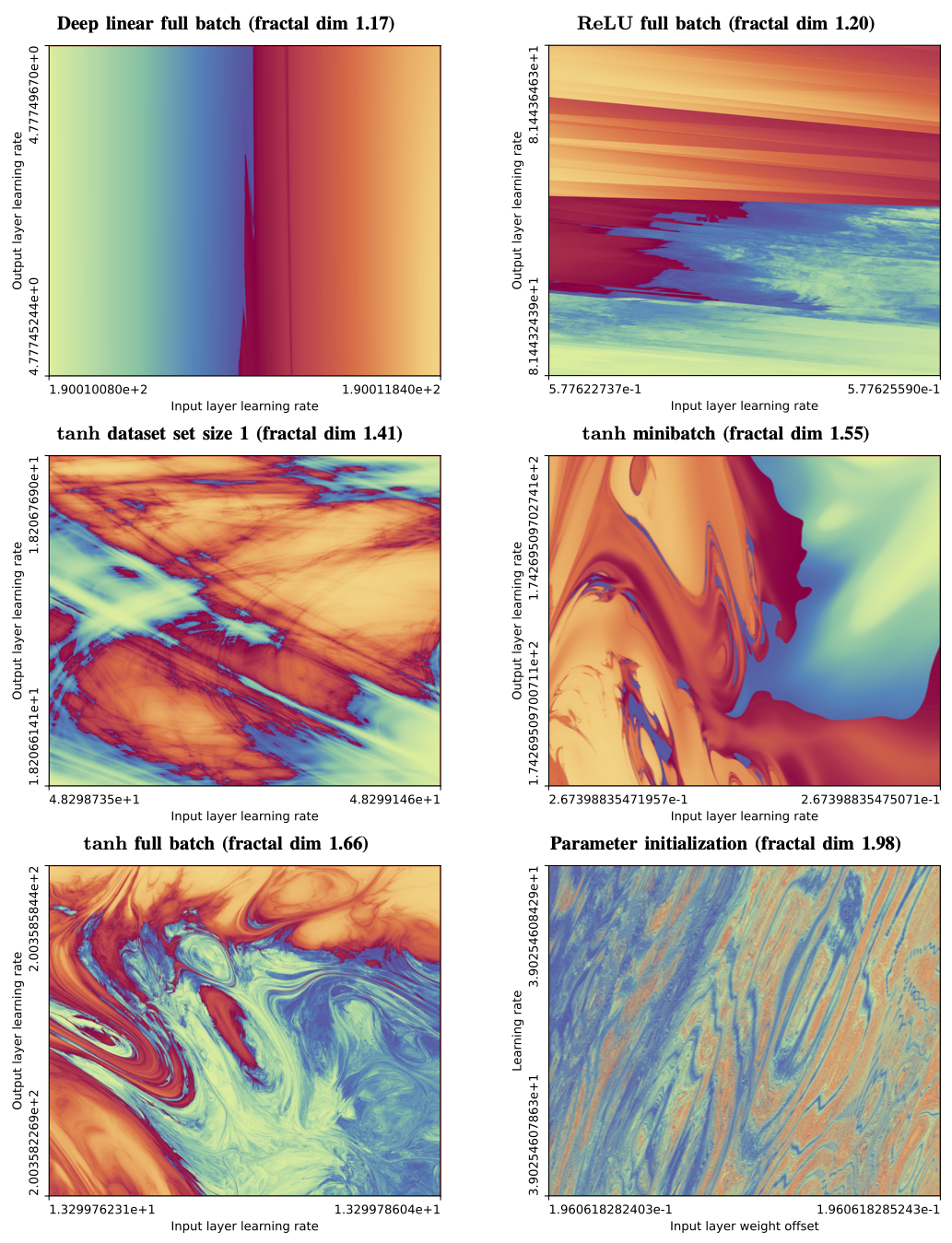
The Fractal Boundary of Trainability
The most interesting region of hyperparameter space is not where training clearly succeeds or clearly fails, but the boundary between the two. This is where learning rates are just stable enough, regularisation is just sufficient, and optimisation teeters on the edge of divergence.
When we zoom into this boundary between convergent (blue) and divergent (red) training regimes, something remarkable happens: structure appears at every scale. Regions that look smooth at coarse resolution reveal increasingly intricate patterns as we zoom in. No matter how closely we examine it, the boundary never simplifies.
In this sense, the boundary of neural network trainability behaves like a fractal. Just as with coastlines or rough surfaces, the distinction between “trainable” and “untrainable” depends on the scale at which we probe it — a reminder that even optimisation lives in a world of fractional geometry.
Scale dependent kinematics: spacetime extension
One intriguing extension is to imagine motion along a fractal path, where the effective distance depends on scale. If $L(\varepsilon) \sim \varepsilon^{1-D}$ is the measured length at scale $\varepsilon$, then a “scale-dependent velocity” $v(\varepsilon)$ could be written as:
For a particle moving in a fractal spacetime geometry, this hints at scale-dependent kinematics, where the observed velocity changes with the measurement resolution, connecting fractal dimension $D$ with the local structure of spacetime.
Conclusions and Final Thoughts
Through this exploration, we have seen how the coastline paradox extends naturally from 2D curves to 3D surfaces, and how it manifests in real-world terrain like Telegraph Hill. Starting with the Koch curve, we visualized the fundamental idea that measured length depends on the scale of measurement. Extending this to 3D, we saw that the surface area of a rough, fractal-like terrain increases as the measurement resolution becomes finer—a phenomenon we’ve called the geographical area paradox.
Applying the same principles to actual GIS data confirmed that this is not just a theoretical curiosity: hilly cities truly do have “more surface” at finer scales, and the apparent area depends on how finely it is measured.
Finally, this journey highlighted the importance of fractional dimensions. Traditional notions of dimension—1D, 2D, 3D—are insufficient to capture the complexity of fractal structures. By calculating Minkowski–Bouligand dimensions from 1D curves, 2D surfaces, and real-world elevation data, we gained a quantitative, scale-invariant measure of roughness.
In the end, the coastline paradox is more than a curiosity: it offers a window into the hidden complexity of the world, from jagged coastlines to hilly terrain, and pushes us to rethink the conventional notion of integer dimensions. Indeed, questioning our intuition about dimensions may be essential for a deeper understanding of concepts like velocity, especially when the underlying physical paths we traverse may be inherently fractal.
]]>
https://franciscormendes.github.io/2025/12/16/3d-coastline-paradox/2025-12-16T00:00:00.000ZDoes a hilly city have more surface area than a flat one? The 3D coastline paradox explored via fractal dimension, Hausdorff measure, and a Python notebook applied to Telegraph Hill.Telegraph Hill and the Coastline Paradox: Measuring a City in Fractional Dimensions2026-04-10T14:24:00.535ZFrancisco Romaldo Fernandes MendesIntroduction
Convolution sits at the heart of modern machine learning—especially convolutional neural networks (CNNs)—yet the underlying mathematics is often hidden behind highly optimised implementations in PyTorch, TensorFlow, and other frameworks. As a result, many of the properties that make convolution such a powerful building block for deep learning become obscured, particularly when we try to reason about model behaviour or debug a failing architecture.
If you know the convolution theorem, a natural question arises:
Why don’t CNNs simply compute a Fourier transform of the input and kernel, multiply them in the frequency domain, and invert the result? Wouldn’t that be simpler and faster?
This blog post addresses exactly that question. We will see that:
FFT-based convolution is not local. In the Fourier domain every coefficient depends on every input pixel. This destroys the locality structure that CNNs rely on to learn hierarchical, spatially meaningful features. As a result, it breaks the very inductive bias that makes CNNs effective.
FFT-based convolution is not computationally cheaper in neural networks. Although FFTs are asymptotically efficient, they must be recomputed on every forward and backward pass—and the cost of repeatedly transforming inputs, kernels, and gradients outweighs any benefit from spectral multiplication.
By the end of this post, we’ll have a clear, explicit comparison—both in matrix form and via backpropagation—showing why CNNs deliberately perform convolution in the spatial domain. Any practioner of signal processing should also be interested in knowing when the “locality” property is useful and when it is not!
1-D Convolution
Let us start with the most basic form of convolution, the 1D convolution. In this case you have a filter (which is nothing but a sequence of numbers) that you want to multiply with your signal in order to produce another signal which is hopefully more interesting to you. For example, in your headphones, you want to multiply a set of numbers with the music signal such that the resulting signal is more music than the wailing baby 1 row behind you.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
import numpy as np
defconv1d_direct(x, h): nx, nh = len(x), len(h) y = np.zeros(nx+nh-1) for n inrange(len(y)): for m inrange(nx): k = n - m if0 <= k < nh: y[n] += x[m] * h[k] return y
x = np.array([1.,2.,0.,-1.]) # this is the signal of music + baby wailing h = np.array([0.5,1.,0.5]) # this is a filter that when multiplied with x makes it more music conv1d_direct(x,h)
Convolution Theorem
This brings us to the convolution theorem wherein we can prove that the process of convolution i.e. multiplying window-wise h and x is mathematically equivalent to a simple multiplication between the fft of h and the fft of x.
1 2 3 4 5 6 7 8 9
defconv_via_fft(x,h): N = len(x)+len(h)-1 X = np.fft.rfft(x,n=N) H = np.fft.rfft(h,n=N) return np.fft.irfft(X*H,n=N)
Just like before before we will convolve a 2D filter with a 2D signal in the spatial domain. We will then, try to do it using the FFT. We will verify that the convolution theorem does indeed work in the 2D space as well.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
defconv2d_direct(img, ker): ih, iw = img.shape kh, kw = ker.shape out = np.zeros((ih+kh-1, iw+kw-1)) for i inrange(out.shape[0]): for j inrange(out.shape[1]): for m inrange(ih): for n inrange(iw): km, kn = i-m, j-n if0 <= km < kh and0 <= kn < kw: out[i,j] += img[m,n] * ker[km,kn] return out
img = np.array([[0,0,0,0],[0,1,2,0],[0,3,4,0],[0,0,0,0]]) ker = np.array([[1,2,1],[2,4,2],[1,2,1]])/16 conv2d_direct(img,ker)
Convolution Theorem 2D
In a similar way to the 1D case instead of windowing and multiplying, we can take the fft of the signal and the kernel and simply multiply.
In a neural network, convolution is used to generate feature maps that feed into the next layer. At first glance, the convolution theorem suggests a tempting shortcut: instead of sliding a kernel spatially, we could transform both the image and kernel into the frequency domain, multiply them element-wise, and transform the result back. The output would be mathematically equivalent—so why not do this inside CNNs?
It turns out there are two fundamental reasons:
Neural networks care about more than just the output—they care about how the output is produced. During backpropagation, each filter weight is updated using gradients derived from local spatial features. This locality enables CNNs to learn hierarchies of edges, textures, shapes, and patterns. In the Fourier domain, however, gradients flow through global Fourier coefficients. Every frequency component depends on every pixel, so the update for a single weight depends on the entire image. This destroys the spatial locality that CNNs rely on and eliminates the inductive bias that makes them effective.
The FFT is not “simpler” computationally for neural networks. While FFTs are efficient in isolation, a CNN would need to repeatedly compute forward FFTs, spectral multiplications, and inverse FFTs—not just for the forward pass, but also for backpropagation. When you count actual multiplications and transforms, the FFT approach is often more expensive, especially for small kernels (e.g., 3×3, 5×5), which dominate modern architectures.
In short: CNNs avoid the Fourier domain because it removes locality and adds computational overhead—both of which undermine the very reasons convolution works so well in deep learning.
2D Spatial Convolution as a Matrix Multiply
For our next trick we will show the exact way in which your hardware actually computes convolutions. Spoiler: it will be some kind of matrix multiplication. This is quite different from the way convolution is taught in the classroom where you usually convolve with a patch of pixels in the spatial domain and roll the kernel onto the next patch nearby. In reality, this whole process is just represented as one huge matrix multiply. It is very important to think about convolution in this way, as it makes approaching complex questions easier. Since looping over pixels is not a coherent mathematical approach whose complexity is easy to compute. Once it is expressed as a matrix multiply between to matrices we can directly use a formula to compute complexity. More importantly, GPUs work fast precisely because they can parallelize this matrix multiply (as opposed to parallizing various kinds of for-loop structures).
In this section, $X$ denotes the input image. It’s worth noting that most deep-learning libraries treat the 2D and 1D cases in essentially the same way: the very first step is to reshape the image into a long vector, commonly written as $\mathrm{vec}(X)$. This operation—often implemented as im2col in the source code—unrolls local patches of the image so that convolution can be expressed as a matrix–vector multiplication.
Eventually these two values will be numerically the same! We know this from the convolution theorem. In the next section we will see that the contributing values matter to the gradient back propagation and that is where the two approaches will differ.
Spatial convolution is cheaper for small kernels, which is why CNNs prefer it.
FFT becomes advantageous only for very large kernels or very large images.
TL;DR
Spatial convolution is efficient for small kernels and preserves locality which is crucial for CNNs to learn hierarchies.
FFT convolution has global interactions, destroys the local inductive bias, and is only computationally advantageous for very large kernels.
Conclusion
We have seen that spatial convolution is not only computationally more efficient but also better suited to capturing the hierarchical structure inherent in most images. For instance, a face detection algorithm may rely on local patterns such as the triangle formed by the eyes and the nose. A kernel that focuses specifically on this local arrangement is highly effective because it preserves locality.
Conversely, in domains like recommendation systems, where data may be represented as a sparse matrix of product–user interactions, capturing global patterns can be more important. Here, the “local” interactions often correspond to users with strong connections, whereas broader, global patterns reveal trends across the entire system. In such contexts, FFT-based approaches—or methods that leverage global connectivity, like graph convolutional networks—can be more appropriate.
This contrast explains why spatial CNNs excel in image-based tasks, while GCNs or FFT-based methods are more suitable for graphs representing global interactions, such as those between users and products.
“A Friendly Introduction to Graph Neural Networks” (Stanford) – Excellent intuition about GCNs and why they differ from CNNs. https://web.stanford.edu/class/cs224w/
]]>
https://franciscormendes.github.io/2025/12/06/convolution/2025-12-06T00:00:00.000ZA unified treatment of 1D signal convolution, 2D image convolution via the convolution theorem, and graph convolution as a spectral operation on the normalized Laplacian.Locality, Learning, and the FFT: Why CNNs Avoid the Fourier Domain2026-04-10T14:24:00.545ZFrancisco Romaldo Fernandes MendesIntroduction
I have always been obsessed with the Fourier Transform, it is in my opinion the single greatest invention in the history of mathematics. Check out this Veritasium video on it! Part of what makes the Fourier Transform so ubiquitous is that any function can be broken down into its component frequencies. What is less well known is that the definition of "frequency" is purely mathematical and applies to a broader class of mathematical objects than just functions! In this post I will try to provide some intuition and visualizations that expand the Fourier Transform to graphs, called the Graph Fourier Transform. Hopefully once that is clear, we will apply the Graph Fourier Transform in a Spectral Graph Convolution Network to model heat propagation in a toroidal surface.
Classical Fourier Transform As A Special Case Of The Graph Fourier Transform
While there are many ways to view the Fourier Transform, the most revealing perspective is to regard it as multiplication of a discrete signal by a special matrix. This viewpoint is useful for several reasons.
Once a signal is discretised, it becomes a vector, and any linear operation on it can be represented as multiplication by a matrix.
A transform is therefore a change of basis: multiplying a vector by a matrix produces a new representation of the same data.
However, only a very small number of matrices yield transformed coordinates that are interpretable. The Fourier matrix $F$ is special because its columns correspond to pure oscillations, which are the eigenvectors of every shift-invariant operator.
A useful transform must also be invertible. After performing operations in the transformed domain, one should be able to recover the original signal exactly. The Fourier matrix satisfies $F^\ast F = N I$, which gives a simple inverse and perfect reconstruction.
Every transform follows the same general recipe:
choose a matrix whose columns represent meaningful basis vectors,
multiply the signal by this matrix,
interpret the transformed coefficients,
use the inverse matrix to return to the original domain.
DFT via the Discrete Laplacian Matrix
We start by deriving the DFT in matrix form for a discrete signal. We will use this as a basis to then derive the Graph Fourier Transform. Consider a 1-D signal sampled at $n$ evenly spaced points: $$x = (x_0, x_1, \dots, x_{n-1})^\top.$$
The continuous Laplacian operator $-\frac{d^2}{dx^2}$ is approximated on a uniform grid by the finite-difference stencil $$f''(i) \approx f(i+1) - 2 f(i) + f(i-1).$$
With periodic boundary conditions, the discrete Laplacian becomes the circulant matrix (keep this in mind when we go to the graph case, we shall see later that this is exactly the Laplacian of a cycle graph):
This matrix discretises the second derivative, $-\frac{d^2}{dx^2}$ on a circle.
Eigenvectors of the Discrete Laplacian
The eigenvectors of $L$ are the complex exponentials $$u_k(j) = \frac{1}{\sqrt{n}} e^{-2\pi i k j / n}, \qquad k = 0, \dots, n-1.$$
These form the DFT basis. Their corresponding eigenvalues are $$\lambda_k = 4 \sin^2\!\left( \frac{\pi k}{n} \right).$$
Thus the discrete Laplacian admits the decomposition $$L = F^\ast \Lambda F,$$ where $F$ is the DFT matrix and $\Lambda = \operatorname{diag}(\lambda_k)$.
Fourier Transform in Matrix Form
Define the DFT matrix $$F_{k,j} = \frac{1}{\sqrt{n}} e^{- 2\pi i k j / n}.$$
The discrete Fourier transform of $x$ is the unitary matrix–vector product $$\hat{x} = F x$$ and the inverse transform is $$x = F^\ast \hat{x}$$.
Interpretation
The classical Fourier transform is therefore the spectral decomposition of the discrete Laplacian on a 1-D grid. Its eigenvectors (complex exponentials) play the role of “frequencies,” and its eigenvalues correspond to squared frequencies: $$L u_k = \lambda_k u_k.$$
So what the heck was the convolution?
Convolution is a local, weighted sum operation over neighbouring inputs. On a 1D signal you would need to use windows and slide them over the signal using the weighted sum operation over all signals in the window.
However, by moving to the spectral domain using the graph Fourier transform, convolution reduces to a simple multiplication: $$\hat{x} = F x,$$ where $F$ is the matrix of eigenvectors of the graph Laplacian and $x$ is the signal on the nodes.
This is crucial because it allows us to avoid explicitly defining a complicated convolution operator. Instead, we can learn filters in the spectral domain that act directly on the eigencomponents of the signal, greatly simplifying the operation while retaining expressive power.
On a graph, performing such a convolution directly is highly nontrivial because the neighbourhoods are irregular. But what if we could mathematically transform the graph to another domain where the operation is a simple multiplcation?