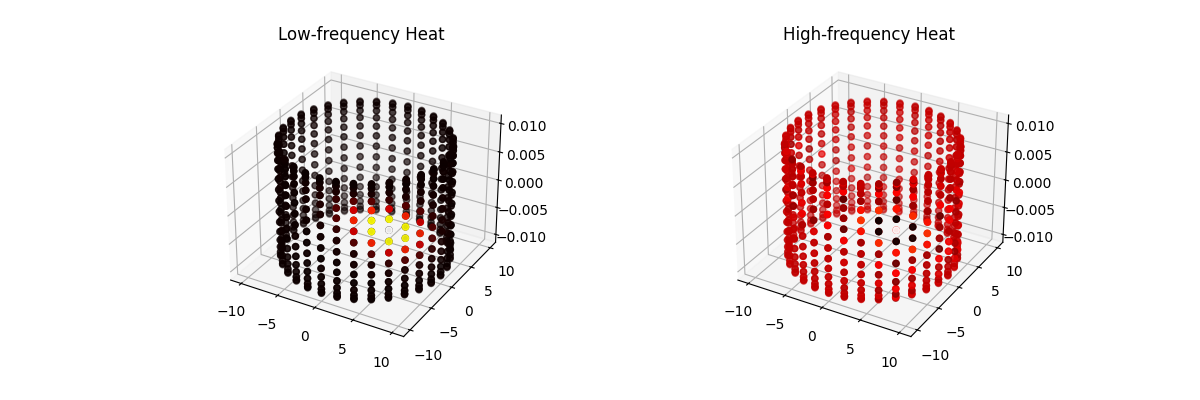
Locality, Learning, and the FFT: Why CNNs Avoid the Fourier Domain
In-Depth Explanation of Various kinds of Convolution: 1D, 2D and Graph
Read more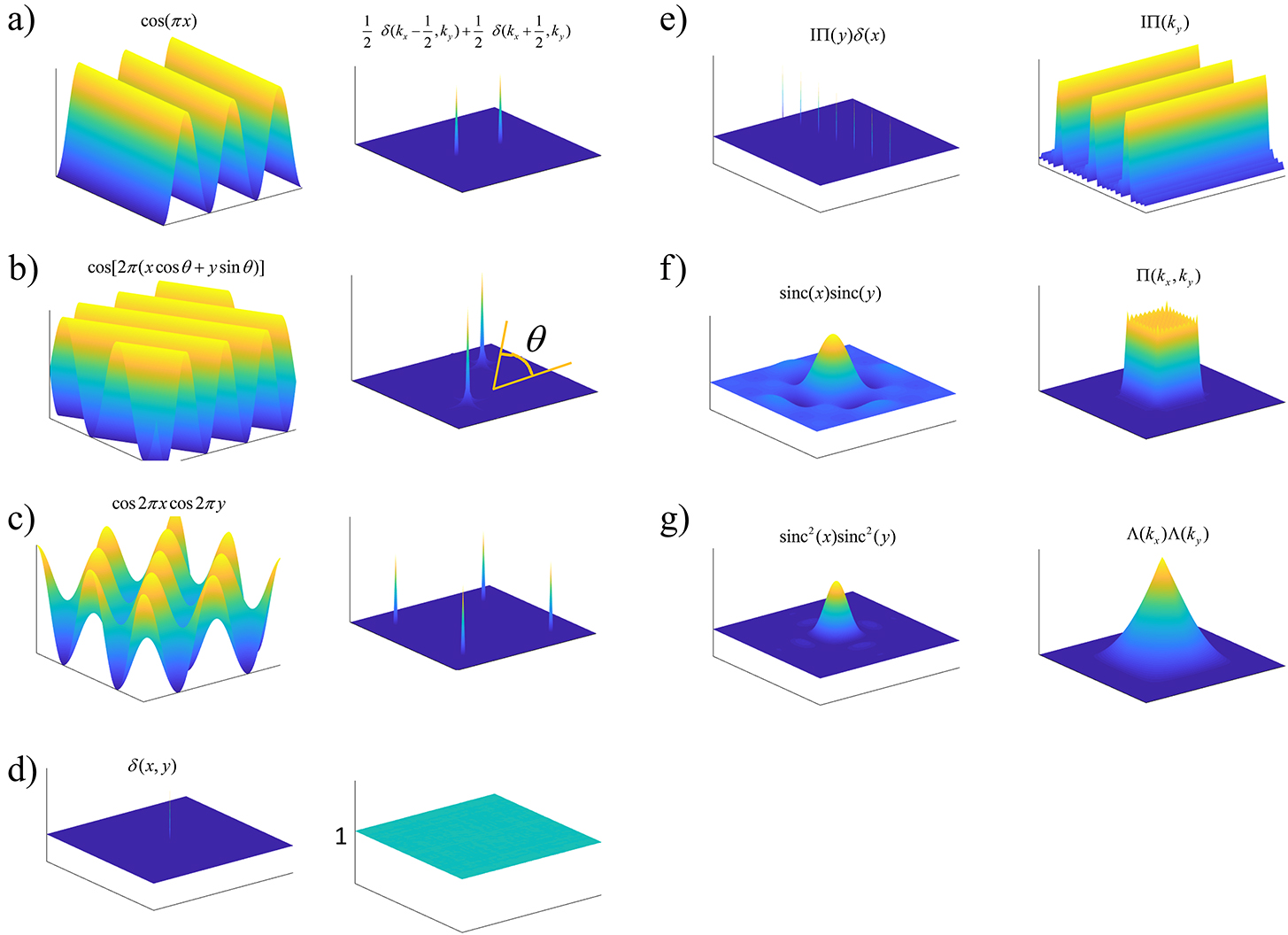
Locality, Learning, and the FFT: Why CNNs Avoid the Fourier Domain

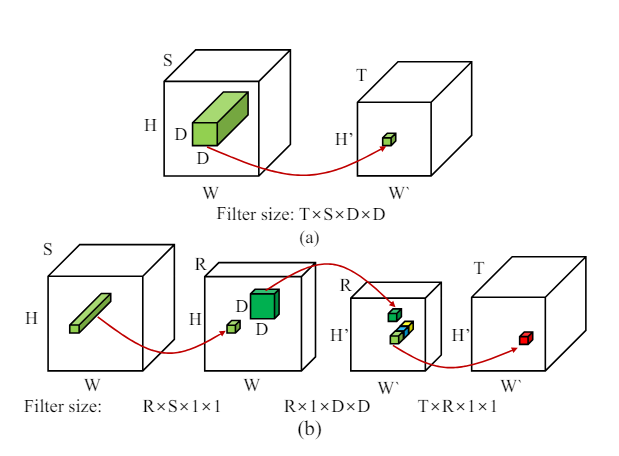
Part III : What does Low Rank Factorization of a Convolutional Layer really do?
Part II : Shrinking Neural Networks for Embedded Systems Using Low Rank Approximations (LoRA)



