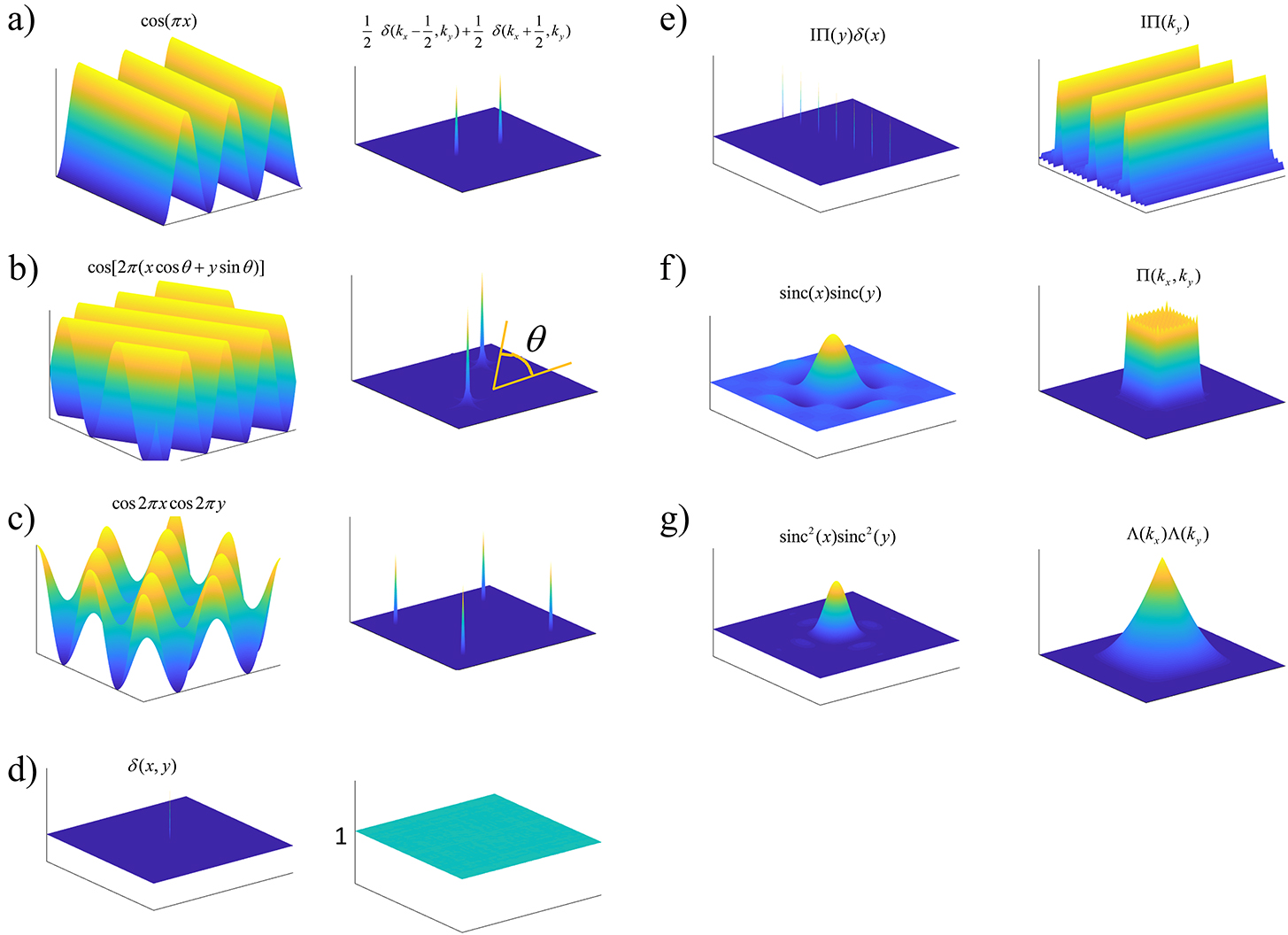
Posted 2025-12-06Updated 2026-02-11artificial-intelligence26 minutes read (About 3884 words)Locality, Learning, and the FFT: Why CNNs Avoid the Fourier DomainIn-Depth Explanation of Various kinds of Convolution: 1D, 2D and GraphRead more
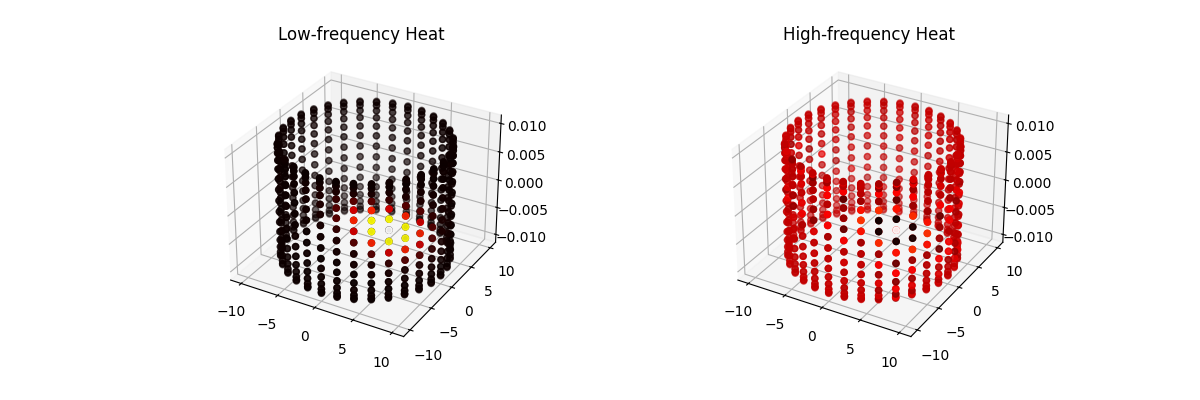
Posted 2025-11-22Updated 2026-02-11artificial-intelligence29 minutes read (About 4415 words)Hot & Cold Spectral GCNs: How Graph Fourier Transforms Connect Heat Flow and Cold-Start RecommendationsExplore how Fourier transforms on graphs power spectral GCNs, from modeling heat flow to solving cold-start recommendations.Read more
Posted 2024-09-28Updated 2026-02-11artificial-intelligence28 minutes read (About 4272 words)Unifying Tensor Factorization and Graph Neural Networks: Review of Mathematical Essentials for Recommender SystemsA review of the mathematical essentials for recommender systems, comparing matrix factorization and graph neural networks.Read more
2026-03-07Beyond Photons: Passive Acoustic Sensing for Autonomous Vehiclesautonomous vehicles / machine learning
2026-02-20Signaling, Skills, and Intellectual Health in the Age of AI: Thoughts from UChicago Career Conference 2026opinion
2025-12-16Telegraph Hill and the Coastline Paradox: Measuring a City in Fractional Dimensionsartificial-intelligence