Locality, Learning, and the FFT: Why CNNs Avoid the Fourier Domain
In-Depth Explanation of Various kinds of Convolution: 1D, 2D and Graph
Read more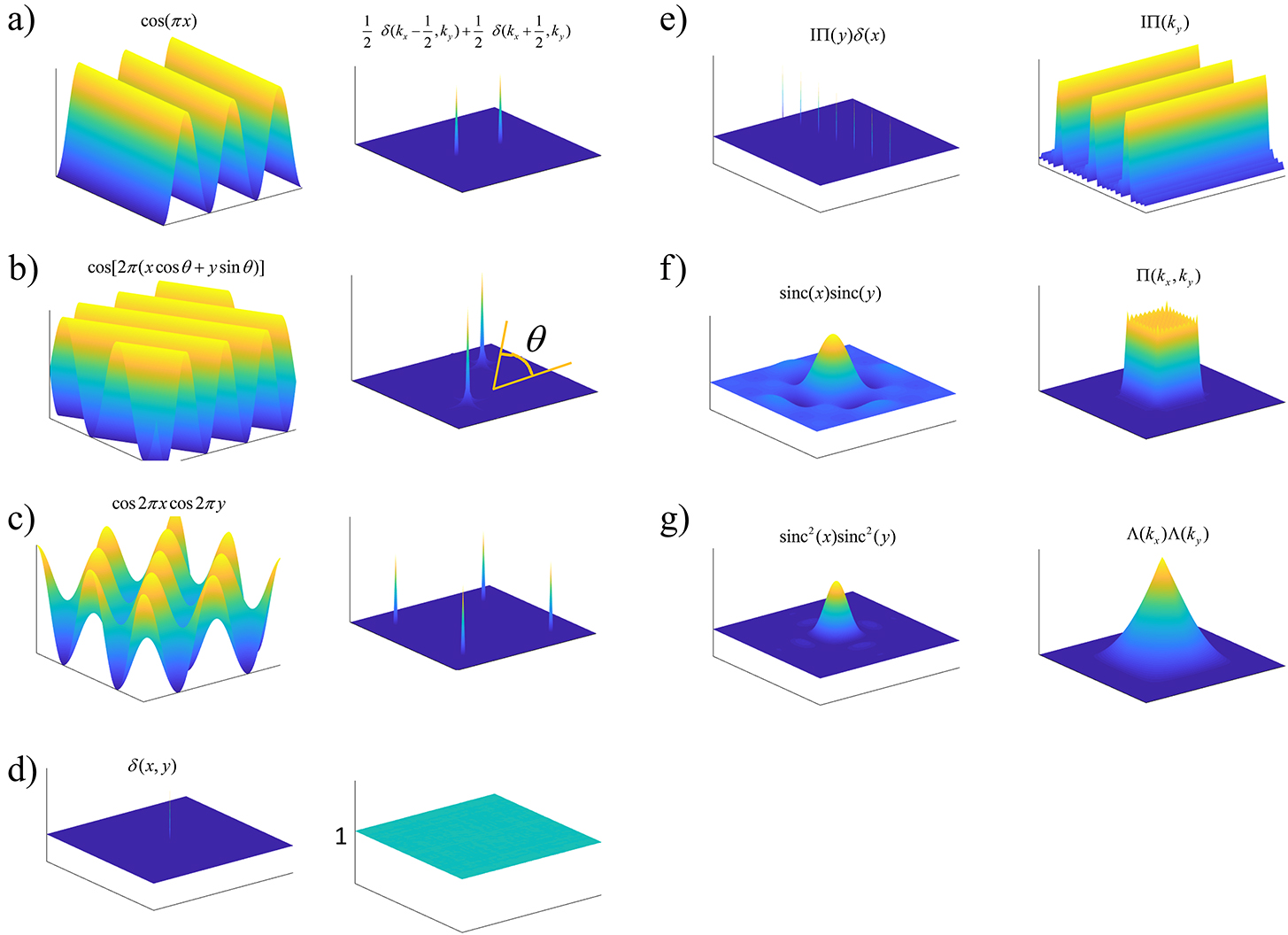
Locality, Learning, and the FFT: Why CNNs Avoid the Fourier Domain
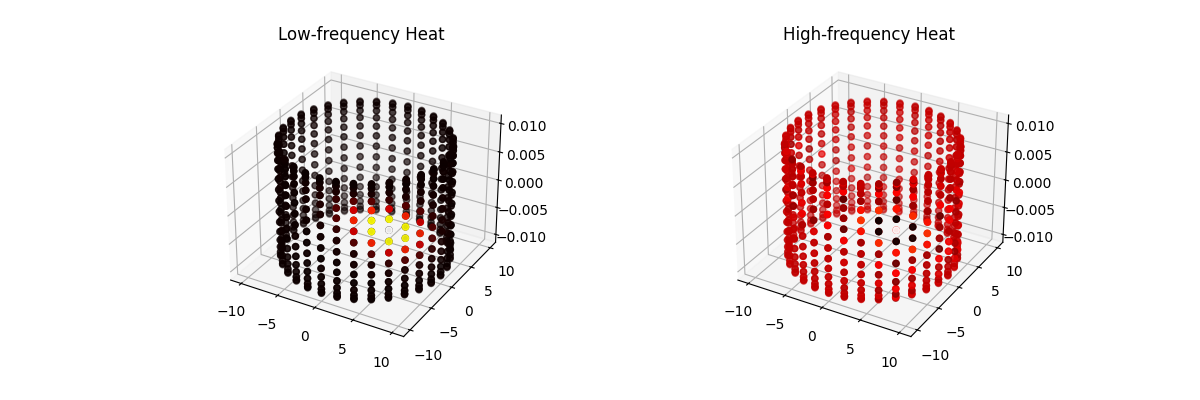
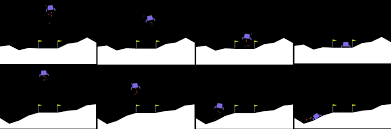
Soft Actor Critic (Visualized) Part 2: Lunar Lander Example from Scratch in Torch

Soft Actor Critic (Visualized) : From Scratch in Torch for Inverted Pendulum

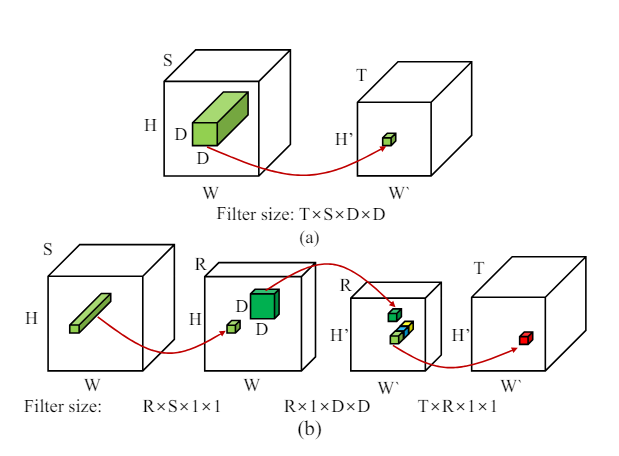
Part III : What does Low Rank Factorization of a Convolutional Layer really do?
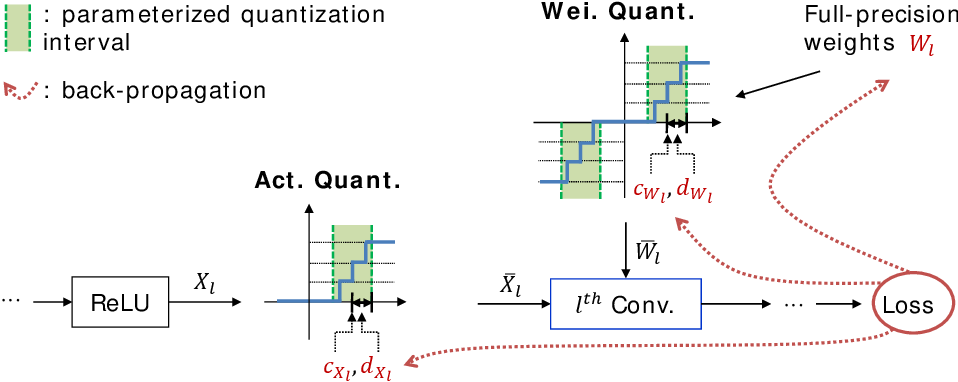
A Manual Implementation of Quantization in PyTorch - Single Layer
Are Values Passed Between Layers Float or Int in PyTorch Post Quantization?
Part II : Shrinking Neural Networks for Embedded Systems Using Low Rank Approximations (LoRA)
Part I : Shrinking Neural Networks for Embedded Systems Using Low Rank Approximations (LoRA)



