A Manual Implementation of Quantization in PyTorch - Single Layer
A manual implementation of quantization in PyTorch.
Read more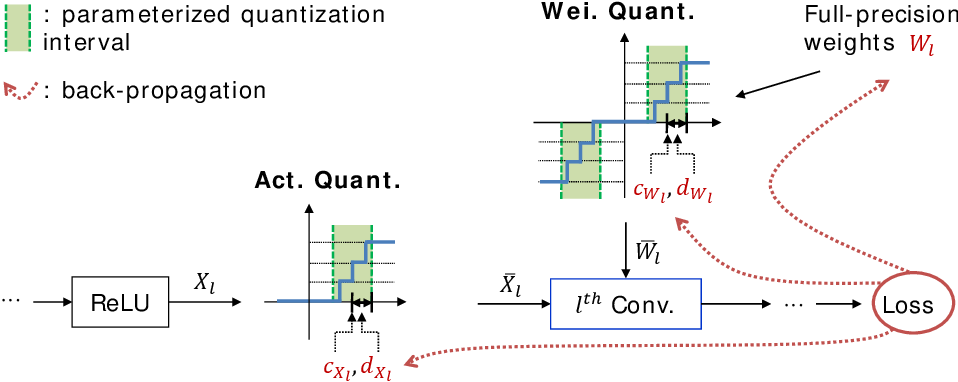
A Manual Implementation of Quantization in PyTorch - Single Layer
Are Values Passed Between Layers Float or Int in PyTorch Post Quantization?